

技术介绍
在JavaScript中,我们可以使用DOM(文档对象模型)来获取div中的HTML代码,DOM是一种编程接口,它允许程序和脚本动态地访问和更新文档的内容、结构和样式,在JavaScript中,我们可以通过各种方式来获取DOM节点,包括通过元素的ID、类名、标签名、属性等。
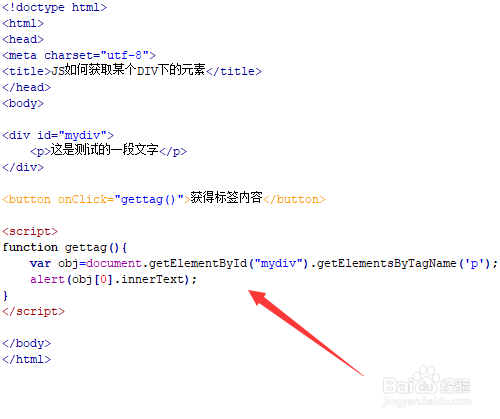

在本题中,我们将使用document.getElementById()方法来获取div元素,然后使用innerHTML属性来获取该元素中的HTML代码。
代码实现
以下是一个简单的示例,演示如何使用JavaScript获取div中的HTML代码:
// 获取id为myDiv的div元素
var div = document.getElementById('myDiv');
// 获取该div元素的HTML代码
var htmlCode = div.innerHTML;
// 打印HTML代码
console.log(htmlCode);
在这段代码中,我们首先使用document.getElementById()方法获取id为myDiv的div元素,我们使用innerHTML属性获取该div元素的HTML代码,我们使用console.log()函数打印出HTML代码。
相关问题与解答
问题1:如果div元素是通过类名而不是id来获取的,应该如何操作?
答:如果div元素是通过类名而不是id来获取的,我们可以使用document.getElementsByClassName()方法来获取元素,这个方法返回一个包含所有具有指定类名的元素的NodeList对象,我们可以遍历这个NodeList对象,对每个元素使用innerHTML属性来获取其HTML代码。
// 获取类名为myClass的div元素
var divs = document.getElementsByClassName('myClass');
// 遍历所有的div元素
for (var i = 0; i < divs.length; i++) {
// 获取每个div元素的HTML代码
var htmlCode = divs[i].innerHTML;
// 打印HTML代码
console.log(htmlCode);
}
问题2:如果div元素中包含了JavaScript生成的内容,如何获取这些内容?
答:如果div元素中包含了JavaScript生成的内容,我们需要确保这些内容已经被渲染到DOM中,然后再使用上述方法来获取它们,我们可以使用setTimeout()函数或者MutationObserver API来等待DOM的更新。
// 创建一个MutationObserver实例
var observer = new MutationObserver(function(mutations) {
mutations.forEach(function(mutation) {
// 如果DOM已经更新,获取div元素的HTML代码并打印出来
if (mutation.type === 'childList') {
var div = document.getElementById('myDiv');
var htmlCode = div.innerHTML;
console.log(htmlCode);
}
});
});
// 配置观察器选项:观察子节点和后代节点的变动情况
var config = { childList: true, subtree: true };
// 开始观察目标节点:target节点是我们要观察的目标节点,这里是document.body;config是观察选项
observer.observe(document.body, config);
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/152290.html
 微信扫一扫
微信扫一扫