

当我们在浏览网页时,可能会遇到HTML显示乱码的问题,这种情况通常是由于编码格式不正确或者浏览器没有正确识别编码导致的,为了解决这个问题,我们需要了解一些基本的HTML编码知识,并学会如何检查和修复乱码问题,本文将详细介绍HTML编码的原理,以及如何解决HTML显示乱码的问题。

HTML编码原理
HTML(HyperText Markup Language)是一种用于创建网页的标记语言,它使用一系列标签来描述网页的内容和结构,在HTML文件中,文本内容通常包含在<body>标签内,为了确保文本内容能够正确显示,我们需要为其指定一个字符编码。
字符编码是一种将字符(如字母、数字和标点符号等)映射到计算机可以识别的二进制数值的方法,常见的字符编码有ASCII、UTF-8、GBK等,不同的字符编码有不同的表示范围和存储方式,因此在使用HTML编写网页时,需要确保文本内容和编码格式之间的一致性。
解决HTML显示乱码的方法
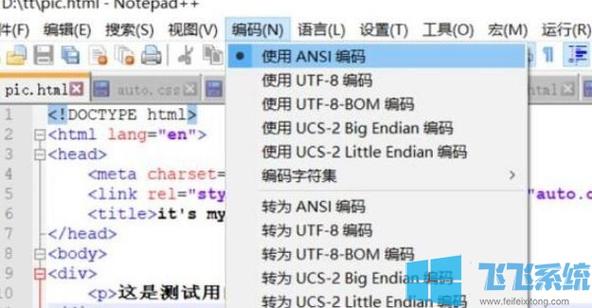
1、检查HTML文件的编码格式
我们需要检查HTML文件的编码格式,可以使用文本编辑器(如Notepad++、Sublime Text等)打开HTML文件,查看其编码格式,如果发现编码格式与实际内容不符,需要将其修改为正确的编码格式。
2、设置HTML文件的字符编码
在HTML文件的开头,通常会有一个<meta>标签,用于指定字符编码。
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
</head>
<body>
...
</body>
</html>
在这个例子中,<meta charset="UTF-8">表示HTML文件使用UTF-8编码,如果发现HTML文件中没有设置字符编码,或者设置的编码格式与实际内容不符,需要将其修改为正确的编码格式。
3、使用浏览器的编码检测功能
有些浏览器提供了编码检测功能,可以帮助我们自动识别并修复乱码问题,以Chrome浏览器为例,我们可以按照以下步骤操作:
(1)右键点击页面空白处,选择“查看网页源代码”;
(2)在弹出的源代码窗口中,点击右上角的菜单按钮(三个竖排的小圆点),选择“编码”->“自动检测编码”;
(3)浏览器会自动检测并尝试修复乱码问题,如果检测成功,页面内容应该会恢复正常显示。
相关问题与解答
1、为什么有时候即使修改了HTML文件的编码格式,仍然会出现乱码?
答:这可能是因为浏览器在解析HTML文件时,已经根据某些线索(如HTTP头部信息、页面中的特定字符等)确定了字符编码,在这种情况下,即使修改了HTML文件的编码格式,浏览器仍然会按照之前的编码格式解析文本内容,导致乱码问题无法解决,为了解决这个问题,可以尝试清除浏览器缓存,或者使用其他浏览器访问页面。
2、除了修改HTML文件的编码格式之外,还有哪些方法可以解决HTML显示乱码的问题?
答:除了修改HTML文件的编码格式之外,还可以尝试以下方法:
(1)使用在线工具进行编码转换:有很多在线工具可以帮助我们将HTML文件从一种编码格式转换为另一种编码格式,https://www.branah.com/unicode;
(2)手动替换乱码字符:如果页面中只有部分内容出现乱码,可以尝试手动替换这些乱码字符为正确的字符;
(3)联系网站管理员:如果上述方法都无法解决问题,可以尝试联系网站管理员,询问他们是否知道乱码问题的原因,并寻求他们的帮助。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/375721.html
 微信扫一扫
微信扫一扫