

在处理网页开发和设计时,我们经常会遇到HTML文件导入后出现乱码的问题,这个问题可能是由于编码问题、文件损坏或者浏览器解析错误等原因导致的,下面我将详细介绍几种解决HTML文件乱码的方法。
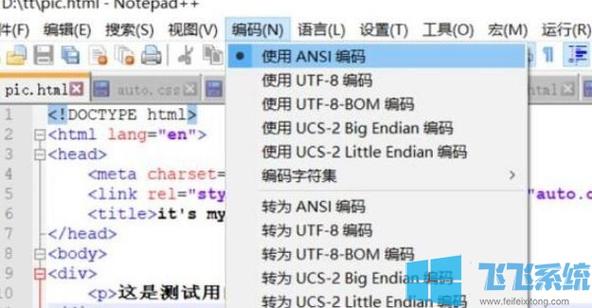

1. 检查并修改文件编码
我们需要检查HTML文件的编码格式是否正确,HTML文件通常使用UTF-8编码,如果你的文件使用的是其他编码,可能会导致乱码,你可以使用文本编辑器(如Notepad++、Sublime Text等)打开文件,查看并修改其编码格式。
2. 使用在线工具进行编码转换
如果文件编码格式正确,但仍然出现乱码,你可以尝试使用在线的编码转换工具,如Convertio等,将文件转换为UTF-8编码。
3. 检查文件是否损坏
如果上述方法都无法解决问题,那么可能是文件本身存在问题,如文件损坏或者被篡改,你可以尝试从原始源获取新的文件,替换掉当前可能损坏的文件。
4. 检查浏览器设置
浏览器的设置也可能导致HTML文件显示乱码,你可以检查浏览器的字符集设置,确保其设置为自动检测或者UTF-8。
5. 使用HTML实体编码
如果HTML文件中包含特殊字符,可能会出现乱码,你可以尝试将这些特殊字符转换为HTML实体编码,如&代表&,"代表"等。
6. 使用CSS样式控制字体
如果HTML文件中的字体不支持某些特殊字符,也可能会出现乱码,你可以尝试使用CSS样式来控制字体,确保字体支持所有需要显示的特殊字符。
以上就是解决HTML文件乱码的一些常见方法,希望对你有所帮助。
相关问题与解答
问题1:为什么HTML文件会出现乱码?
答:HTML文件出现乱码的原因有很多,可能是由于文件编码不正确、文件损坏、浏览器解析错误、特殊字符未转换为HTML实体编码、字体不支持某些特殊字符等原因导致的。
问题2:如何确定HTML文件的编码格式?
答:你可以通过文本编辑器打开HTML文件,查看其编码格式,大部分文本编辑器都会在底部的状态栏显示当前的编码格式,如果没有显示,你也可以尝试手动更改编码格式,看哪种编码格式能够正常显示文件中的内容,你还可以使用在线的编码检测工具,如Charset Checker等,来检测HTML文件的编码格式。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/375932.html
 微信扫一扫
微信扫一扫