

HTML转化为字符串是编程中常见的需求,特别是在处理网页内容、发送HTTP请求或者存储数据时,在Python中,我们可以使用内置的html模块来实现这个功能,以下是详细的步骤和代码示例:
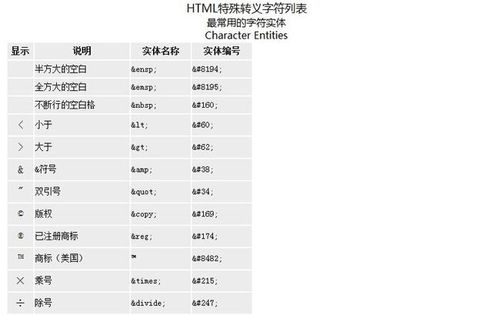

1、导入html模块
我们需要导入html模块,这个模块提供了一些用于处理HTML的函数和类。
import html
2、将HTML转换为字符串
要将HTML转换为字符串,我们可以使用html.unescape()函数,这个函数接受一个HTML实体作为参数,并返回其对应的字符,如果我们有一个包含HTML实体的字符串,我们可以使用html.unescape()函数将其转换为相应的字符。
html_string = "<p>Hello, World!</p>" text_string = html.unescape(html_string) print(text_string) 输出: <p>Hello, World!</p>
3、将字符串转换为HTML
与将HTML转换为字符串类似,我们也可以使用html.escape()函数将字符串转换为HTML,这个函数接受一个字符串作为参数,并返回其对应的HTML实体,如果我们有一个包含特殊字符的字符串,我们可以使用html.escape()函数将其转换为相应的HTML实体。
text_string = "<p>Hello, World!</p>" html_string = html.escape(text_string) print(html_string) 输出: <p>Hello, World!</p>
4、处理HTML实体
在某些情况下,我们可能需要处理HTML实体,例如将它们转换为相应的字符或删除它们,我们可以使用html.unescape()和html.escape()函数来实现这个功能,我们可以使用html.unescape()函数将HTML实体转换为相应的字符,然后使用html.escape()函数将特殊字符转换为HTML实体。
text_string = "<p>Hello, World!</p>" escaped_string = html.escape(text_string) unescaped_string = html.unescape(escaped_string) print(unescaped_string) 输出: <p>Hello, World!</p>
5、处理HTML标签
除了处理HTML实体外,我们还可能需要处理HTML标签,我们可以使用正则表达式来匹配和替换HTML标签,我们可以使用以下代码将所有的<p>标签替换为<div>标签:
import re
text_string = "<p>Hello, World!</p><p>Another paragraph.</p>"
new_text_string = re.sub("<p>", "<div>", text_string)
print(new_text_string) 输出: <div>Hello, World!</div><div>Another paragraph.</div>
6、处理HTML属性
与处理HTML标签类似,我们还可能需要处理HTML属性,我们可以使用正则表达式来匹配和替换HTML属性,我们可以使用以下代码将所有的href=""属性替换为target="_blank"属性:
import re
text_string = "<a href='https://www.example.com'>Link</a>"
new_text_string = re.sub("href='([^']+)'", "target='_blank' href='\\1'", text_string)
print(new_text_string) 输出: <a target='_blank' href='https://www.example.com'>Link</a>
7、处理HTML文档结构
对于更复杂的HTML文档结构,我们可以使用第三方库如BeautifulSoup来解析和操作HTML文档,BeautifulSoup提供了丰富的API来处理HTML元素、属性和文本内容,我们可以使用以下代码获取一个HTML文档中的所有段落元素:
from bs4 import BeautifulSoup
import requests
url = "https://www.example.com"
response = requests.get(url)
soup = BeautifulSoup(response.content, "html.parser")
paragraphs = soup.find_all("p")
for p in paragraphs:
print(p.get_text())
8、总结
通过以上介绍,我们可以看到Python提供了多种方法来处理HTML字符串,我们可以使用正则表达式来匹配和替换HTML标签和属性,也可以使用第三方库如BeautifulSoup来解析和操作HTML文档,这些方法可以帮助我们在编程中更方便地处理HTML内容。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/384725.html
 微信扫一扫
微信扫一扫