

获取HTML5源码通常指的是从网页中提取出构成该网页的HTML5标记语言代码,这通常涉及几个不同的方法,包括直接访问网站源代码、使用开发者工具、以及通过APIs等,以下是详细的技术介绍:

直接访问网站源代码
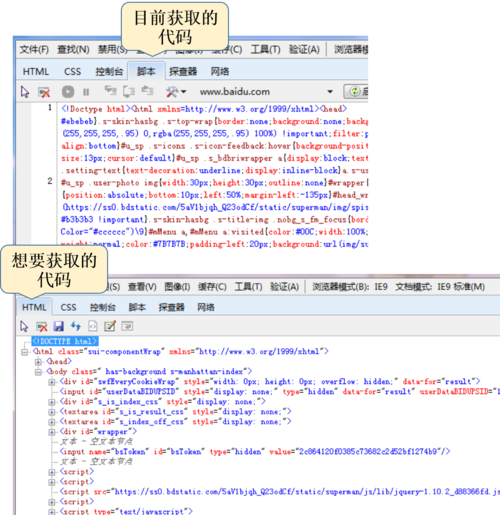
1、浏览器查看: 在大多数现代浏览器中,你可以通过右键点击页面,选择“查看页面源代码”或按下键盘快捷键(如Ctrl+U在大多数浏览器中),来查看网页的源代码,这将打开一个新窗口,显示当前页面的完整HTML内容。
2、源代码的局限性: 需要注意的是,这样看到的HTML可能包含一些动态加载的内容,比如通过JavaScript生成的部分,可能不会完全显示。
使用开发者工具
1、开发者工具: 几乎所有现代浏览器都配备了开发者工具,它允许你深入检查网页的结构和样式,通过右键菜单中的“检查元素”或使用快捷键(如Ctrl+Shift+I),可以打开开发者工具。
2、Elements面板: 在开发者工具的Elements面板中,你可以查看到页面的HTML结构,并实时看到任何由JavaScript引起的更改。
3、网络请求: Network面板则展示了网页加载过程中所有的网络请求,包括HTML文档、CSS文件、JavaScript脚本和图片等资源。
4、保存网页: 在开发者工具中,还可以将整个网页保存下来,通常这个选项位于菜单中,可以选择保存为完整的HTML文档,包括所有相关的资源。
使用APIs和库
1、Web APIs: 对于需要程序化访问HTML源码的情况,可以使用Web APIs,例如使用JavaScript的fetch或XMLHttpRequest来获取其他网页的HTML内容。
2、第三方库: 有一些第三方库,比如Node.js中的axios、request或Python中的requests库,可以帮助你更容易地发送HTTP请求并获取响应内容。
注意事项
1、权限和合法性: 在尝试获取任何网站的HTML源码时,请确保你遵守了相关法律和政策,特别是关于隐私和版权的规定。
2、动态内容: 由于很多现代网页使用了大量的JavaScript来动态渲染内容,单纯获取初始的HTML代码可能无法获得全部信息,在这种情况下,可能需要借助浏览器自动化工具,例如Puppeteer,来模拟用户交互并捕获动态生成的内容。
3、跨域问题: 如果你尝试从一个域名获取另一个域名的HTML内容,可能会遇到所谓的跨域问题,这时,服务器必须设置适当的CORS策略,否则你的请求可能会被浏览器阻止。
相关问题与解答
Q1: 如果网页使用了防爬虫技术,我还能获取它的HTML5源码吗?
A1: 防爬虫技术确实会给获取HTML源码带来难度,不过,你可以尝试使用更先进的工具和方法,例如使用代理服务器、伪装User-Agent、处理CAPTCHA或者使用headless浏览器等技术来绕过限制。
Q2: 我能否通过编程方式定期自动获取特定网页的HTML5源码?
A2: 是的,你可以编写脚本或程序,使用定时任务(如cron jobs)配合HTTP请求库(如Python的requests、Node.js的axios)来定期获取网页源码,请确保这样做符合目标网站的服务条款,且不对服务器造成过大负担。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/396715.html
 微信扫一扫
微信扫一扫