

MHT文件格式是一种由微软Outlook Express和IE浏览器使用的Web存档文件格式,它用于保存HTML网页及其关联的图像、样式表和其他资源,将MHT文件转换为HTML的过程涉及到提取MHT文件中的内容并将其重新组织为标准的HTML格式,以下是详细的技术介绍:

理解MHT和HTML格式
在深入转换过程之前,需要了解MHT和HTML格式之间的区别:
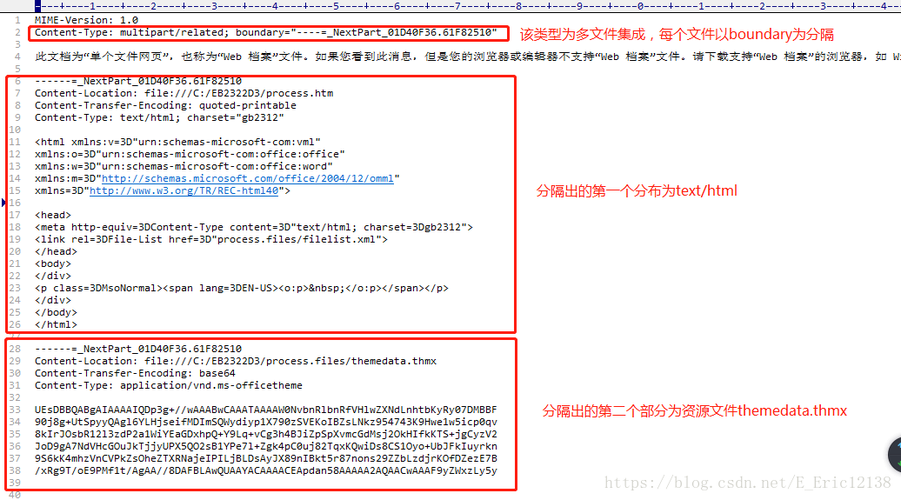
MHT: MHT(MIME HTML)文件通常包含了完整的网页内容,包括文本、图片、样式等,且所有这些数据都以单一文件的形式存储。
HTML: HTML(HyperText Markup Language)是构建网页的标准标记语言,通常与CSS和JavaScript文件分开使用,每个文件各自独立。
转换工具的选择
有多种软件和在线服务可以帮助你将MHT文件转换成HTML,这些工具通常提供了一种快速且不需要编程知识的方法来完成转换,以下是一些常见工具:
在线转换器: 例如Zamzar、FileZigZag等提供在线文件转换服务的网站。
桌面软件: 如WinMHT, MHT to HTML Converter等,它们提供了图形界面来执行转换。
手动转换方法
如果你希望手动进行转换,或者对自动化工具的结果不满意,可以采取以下步骤:
1、提取内容: 使用像7-Zip这样的压缩工具打开MHT文件,因为它实际上是一个打包成单个文件的网站。
2、重组结构: 解压后,你会看到一个包含HTML、图片和其他资源的文件夹,需要将这些资源重新组织成一个标准的网站结构。
3、编辑HTML: 可能需要对解压出的HTML文件进行一些修改,以确保所有的链接、图片路径等都是正确的。
4、测试: 在完成编辑后,使用任何Web浏览器打开HTML文件,检查页面是否按预期显示。
这种方法需要一定的技术知识和耐心,因为可能会遇到路径问题、编码问题等。
编程转换方法
对于有编程背景的用户,可以通过编写脚本来实现MHT到HTML的转换,以下是一个基于Python的简单示例:
import os import zipfile def extract_mht(mht_path): with zipfile.ZipFile(mht_path, 'r') as mht_zip: mht_zip.extractall('output_folder') def convert_to_html(output_folder): 这里你可以添加代码来处理提取出的文件,并转换为适合的HTML结构 pass if __name__ == "__main__": mht_path = 'path_to_your_mht_file.mht' output_folder = 'path_to_output_folder' extract_mht(mht_path) convert_to_html(output_folder)
此脚本使用Python的zipfile模块来解压MHT文件,你需要在convert_to_html函数中添加逻辑来处理和转换解压出来的文件。
相关问题与解答
Q1: 转换过程中图片丢失怎么办?
A1: 如果在使用自动化工具或手动方法转换时发现图片丢失,首先确保MHT文件中的所有资源都被正确解压,然后检查HTML中的图像链接是否正确指向解压后的图片位置,如果有必要,更新图像链接或移动图片文件以确保它们可以被找到。
Q2: 转换后的HTML在不同的浏览器中显示不一致怎么办?
A2: 如果在转换后的HTML在不同浏览器中出现显示不一致的情况,这可能是由于浏览器对HTML和CSS的解释存在差异,为了解决这个问题,需要确保使用的HTML和CSS代码遵循标准规范,并进行跨浏览器测试,可能需要添加特定的浏览器前缀或使用跨浏览器兼容的代码。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/401442.html
 微信扫一扫
微信扫一扫