

在Web开发中,HTML页面中文显示乱码是一个常见的问题,要解决这个问题,我们需要理解字符编码的基本概念以及如何在HTML页面中正确设置编码。

字符编码简介
计算机存储和处理文字信息时,需要将文字转换成计算机能够识别的二进制代码,这个过程称为字符编码,世界上存在多种字符编码标准,如ASCII、ISO-8859系列、GB2312、GBK、UTF-8等。
ASCII:美国信息交换标准码,只能表示英文字符。
ISO-8859系列:国际标准组织推出的多字节编码标准,有多种变体,每种支持不同的语言。
GB2312/GBK:中国大陆使用的汉字编码标准。
UTF-8:Unicode的一种实现方式,可以编码全世界所有的文字符号。
为什么会出现中文乱码
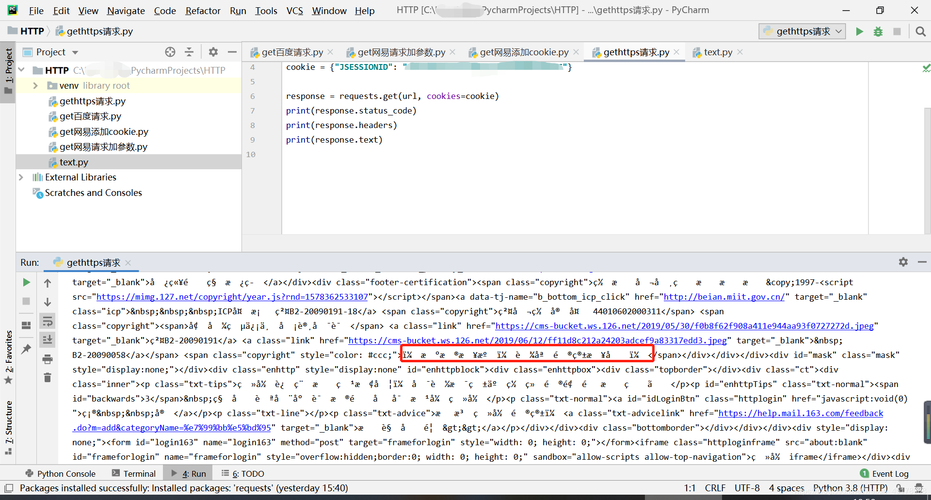
中文乱码出现的原因通常是由于字符编码设置不一致导致的,当浏览器解析HTML文档时,如果HTML文档声明的字符编码与实际文件的编码不一致,就会出现乱码。
HTML如何输出中文避免乱码
1. 设置正确的HTTP头信息
确保服务器返回的HTTP响应头中的Content-Type字段包含正确的字符编码声明。
Content-Type: text/html; charset=utf-8
这告诉浏览器页面使用UTF-8编码。
2. 在HTML文档中声明字符编码
在HTML文档的<head>区域内,使用<meta>标签声明字符编码。
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
...
</head>
<body>
...
</body>
</html>
这里声明了文档使用UTF-8编码。
3. 选择合适的字符编码
根据实际需求选择适合的字符编码,对于中文网站,通常推荐使用UTF-8编码,因为它可以兼容各种语言字符,并且是Web的国际标准编码。
4. 检查编辑器和服务器配置
确保你的文本编辑器和Web服务器都设置为使用你选择的字符编码,如果你选择了UTF-8,则应确保编辑器保存文件时使用UTF-8,服务器也配置为使用UTF-8。
5. 避免硬编码中文字符串
尽量不要在HTML或JavaScript代码中直接硬编码中文字符串,而是通过外部文件(如JSON、XML等)加载,并确保这些文件也是用正确的编码保存的。
常见问题排查
如果按照以上方法操作后仍然出现乱码,可以进行以下检查:
确认源代码文件的编码是否与声明的编码一致。
检查是否有第三方资源(如图片、脚本、样式表)的路径或编码不正确。
查看Web服务器的配置是否正确设置了字符编码。
确认浏览器是否自动转换编码,有些浏览器会根据页面内容推测编码。
相关问题与解答
问:如果我的网页主要是英文,但偶尔有少量中文字符,我应该如何设置编码?
答:即使主要文本是英文,只要页面中包含非ASCII字符(如中文),最佳实践还是使用UTF-8编码,因为它可以无障碍地处理包括中文在内的任何字符。
问:我的网站需要支持多种语言,我该如何保证不会出现乱码问题?
答:对于多语言网站,强烈建议使用UTF-8编码,因为它是国际化的标准,并且支持几乎所有的语言字符,确保所有涉及到文本处理的环节(包括数据库存储、后端处理、前端展示)均使用UTF-8编码,以保持统一性。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/401955.html
 微信扫一扫
微信扫一扫