HTML(HyperText Markup Language)是用于创建网页的一种标记语言,而Excel指的是Microsoft Excel电子表格软件,通常用于数据分析和报告,将HTML转换为Excel涉及提取HTML中的数据并将其导入到Excel工作表中,这个过程可以通过以下几个步骤实现:
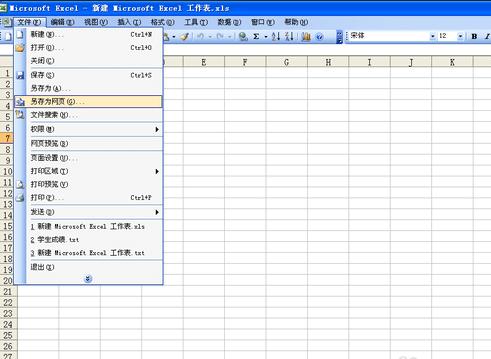
手动复制粘贴
1、打开含有所需数据的HTML页面。
2、选中并复制你想要的数据。
3、打开Excel。
4、在工作表中选择粘贴数据的位置。
5、使用"粘贴特殊"功能,选择适合的选项,如“文本”或“HTML格式”,以正确粘贴数据。
这种方法适用于数据量小且结构不复杂的情况。
使用Excel的“获取和转换数据”功能
Excel有一个功能强大的数据导入工具叫做“获取和转换数据”(也称为Power Query),可以用来从多种来源导入数据,包括HTML文件。
1、打开Excel。
2、选择“数据”选项卡。
3、点击“从其他源获取数据”下拉菜单中的“来自Web”。
4、在弹出的对话框中输入HTML页面的URL。
5、选择表或数据区域并加载到工作表中。
这个方法可以自动处理一些数据格式的问题,但可能需要对导入的数据进行后续清理和格式化。
使用第三方软件或服务
有许多第三方应用程序和服务可以将HTML内容转换为Excel格式,
在线转换工具: 通过搜索“HTML to Excel converter”可以找到许多免费的在线服务,只需上传你的HTML文件,它们会自动处理转换过程。
桌面软件: 如Adobe Acrobat等PDF工具经常提供将HTML转换为Excel的功能。
编写脚本或程序
如果你有编程技能,可以编写脚本来自动化这一过程,比如使用Python的pandas库结合BeautifulSoup解析HTML并提取数据,然后输出为Excel文件。
import pandas as pd
from bs4 import BeautifulSoup
读取HTML文件
with open("data.html", "r") as file:
content = file.read()
soup = BeautifulSoup(content, 'html.parser')
假设数据在一个表格内,提取表格数据
table = soup.find('table')
rows = table.find_all('tr')
提取表格行数据
data = []
for row in rows:
cols = row.find_all('td')
cols = [col.text.strip() for col in cols]
data.append(cols)
创建一个DataFrame并输出为Excel文件
df = pd.DataFrame(data)
df.to_excel('output.xlsx', index=False)
以上代码是一个简单示例,实际情况下你可能需要根据具体的HTML结构调整数据提取逻辑。
相关问题与解答
Q1: HTML中的哪些元素通常包含需要转换到Excel中的数据?
A1: 通常,数据存储在HTML的<table>元素中,特别是<tr>(表行)和<td>(表单元格)标签内,有时也可能在<div>或<ul>等其他元素中,具体取决于网页的设计。
Q2: 如果HTML文件中的数据格式不一致,如何确保转换后的数据在Excel中准确无误?
A2: 数据格式不一致时,可能需要在转换过程中加入数据清洗和验证的步骤,可以使用Excel的“文本分列”功能、公式或者利用编程语言(如Python)中的数据处理库来确保数据的准确性,在转换前检查HTML源码,理解其结构,有助于设计出合适的数据提取和处理策略。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/408343.html
 微信扫一扫
微信扫一扫