

云服务器可通过安装数据采集软件或API接口,定期或实时采集数据,存储在数据库中进行分析。
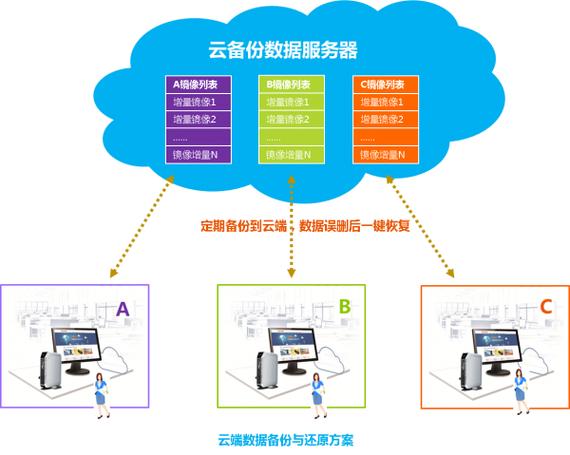

云服务器采集数据的过程可以分为以下几个步骤:
1、选择合适的数据采集工具和库
Python:可以使用requests、BeautifulSoup等库进行网页抓取和解析。
Java:可以使用Jsoup、HttpClient等库进行网页抓取和解析。
Node.js:可以使用axios、cheerio等库进行网页抓取和解析。

2、编写数据采集程序
根据需求,编写相应的数据采集程序,实现数据的抓取、解析和存储。
3、部署数据采集程序到云服务器
将编写好的数据采集程序部署到云服务器上,确保程序能够正常运行。
4、配置定时任务
使用云服务器的定时任务功能,设置数据采集程序的运行时间和频率。
5、监控数据采集情况
通过查看日志、分析数据等方式,监控数据采集程序的运行情况,确保数据采集顺利进行。
以下是一个简单的Python爬虫示例,用于采集网页上的数据:
import requests
from bs4 import BeautifulSoup
目标网址
url = 'https://example.com'
发送请求,获取网页内容
response = requests.get(url)
content = response.text
使用BeautifulSoup解析网页内容
soup = BeautifulSoup(content, 'html.parser')
提取所需数据,例如提取所有的标题
titles = soup.find_all('h1')
打印提取到的数据
for title in titles:
print(title.text)
在云服务器上运行此爬虫程序,可以实现对指定网址的数据进行采集。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/420746.html
 微信扫一扫
微信扫一扫