

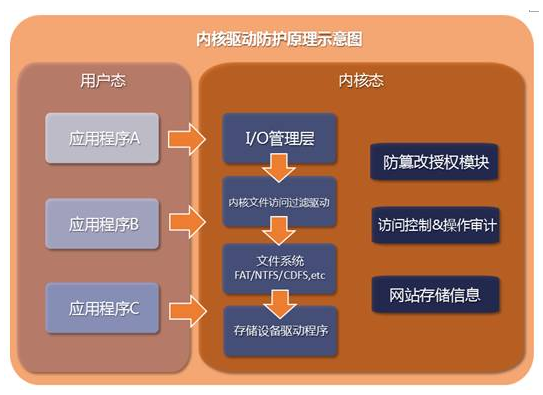

网页防篡改是一种保护网站内容不被非法修改的技术手段,它基于以下几个原理:
1、服务器端校验:
原理:通过在服务器端对网页文件进行校验,确保文件的完整性和一致性。
方法:使用哈希算法(如MD5、SHA1等)对网页文件进行加密,生成唯一的哈希值,每次访问时,重新计算哈希值并与原始哈希值进行比对,如果不一致则说明文件被篡改。
2、客户端校验:
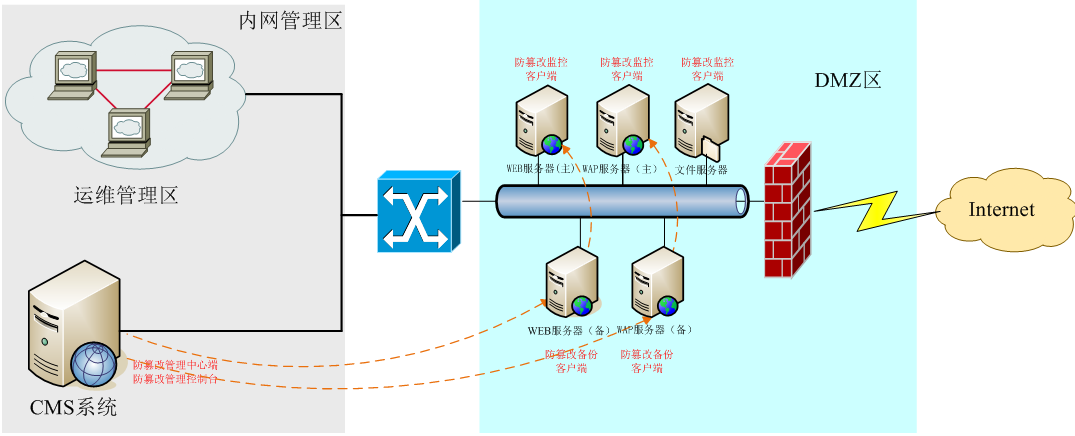
原理:通过在客户端对网页文件进行校验,确保用户获取到的是未经篡改的内容。
方法:将网页文件的哈希值嵌入到HTML代码中,当用户访问网页时,浏览器会自动计算网页文件的哈希值并与嵌入的哈希值进行比对,如果不一致则提示用户网页被篡改。
3、实时监控:
原理:通过实时监控网页文件的变化,及时发现并阻止非法修改。
方法:使用文件监控系统(如Inotify、FileSystemWatcher等)对网页文件进行实时监控,一旦发现文件被修改,立即触发报警或自动恢复机制。
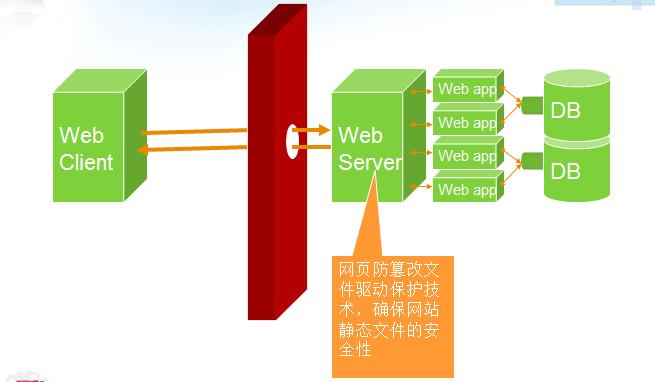
4、备份与恢复:
原理:定期对网页文件进行备份,以便在文件被篡改后能够快速恢复到原始状态。
方法:将网页文件备份到安全的地方,如远程服务器或云存储服务,当发现文件被篡改时,可以使用备份文件进行恢复。
5、权限控制:
原理:通过限制对网页文件的访问和修改权限,防止非法用户篡改网页内容。
方法:为网页文件设置适当的权限,如只允许特定的用户或用户组访问和修改,使用防火墙和安全软件限制外部访问,防止恶意攻击。
6、日志分析:
原理:通过对服务器日志进行分析,发现异常行为并追踪篡改者。
方法:记录服务器的操作日志,包括文件访问、修改、删除等操作,定期分析日志,查找异常行为,如多次尝试修改同一文件、非正常时间段的操作等,从而追踪篡改者。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/420778.html
 微信扫一扫
微信扫一扫