


临界区是指并发进程中访问共享变量的一段代码,在多线程或多进程环境中,多个线程或进程可能会同时访问和修改共享变量,这可能导致数据不一致的问题,为了避免这种情况发生,需要将访问共享变量的代码放在一个临界区内,确保在任何时刻只有一个线程或进程能够进入该区域。
下面是一个示例,展示了如何使用小标题和单元表格来说明临界区的概念:
临界区的概念
临界区是并发进程中访问共享变量的一段代码,它用于保护共享资源,防止多个线程或进程同时访问和修改共享变量,从而避免数据不一致的问题。
临界区的实现方式
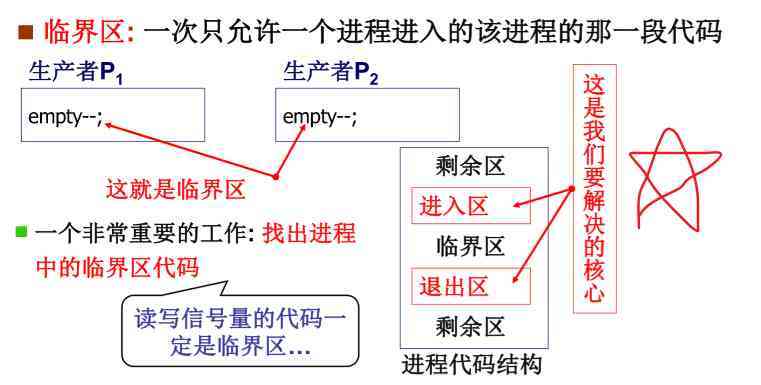
有多种方法可以实现临界区的保护,其中最常见的是使用互斥锁(Mutex),互斥锁是一种同步原语,用于控制对共享资源的访问,当一个线程或进程获得互斥锁时,其他线程或进程必须等待,直到该锁被释放才能进入临界区。
以下是一个简单的示例,展示了如何使用互斥锁来实现临界区的保护:
import threading
定义共享变量
shared_variable = 0
创建互斥锁
mutex = threading.Lock()
def increment():
# 获取互斥锁
mutex.acquire()
try:
# 执行临界区代码
global shared_variable
shared_variable += 1
finally:
# 释放互斥锁
mutex.release()
创建多个线程并启动它们
threads = []
for i in range(5):
thread = threading.Thread(target=increment)
threads.append(thread)
thread.start()
等待所有线程完成
for thread in threads:
thread.join()
print("最终结果:", shared_variable)
在上面的示例中,increment函数中的代码块就是临界区,它访问和修改了共享变量shared_variable,通过使用互斥锁,我们确保在任何时刻只有一个线程能够进入临界区,从而避免了数据不一致的问题。
相关问题与解答
问题1:为什么需要使用临界区?

解答:并发进程中的多个线程或进程可能会同时访问和修改共享变量,这可能导致数据不一致的问题,使用临界区可以确保在任何时刻只有一个线程或进程能够进入临界区,从而保护共享资源,避免数据不一致的情况发生。
问题2:除了互斥锁,还有哪些方法可以实现临界区的保护?
解答:除了互斥锁,还有其他一些方法可以实现临界区的保护,例如使用信号量、条件变量等,不同的方法适用于不同的场景和需求,可以根据具体情况选择合适的方法来实现临界区的保护。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/448373.html
 微信扫一扫
微信扫一扫 