

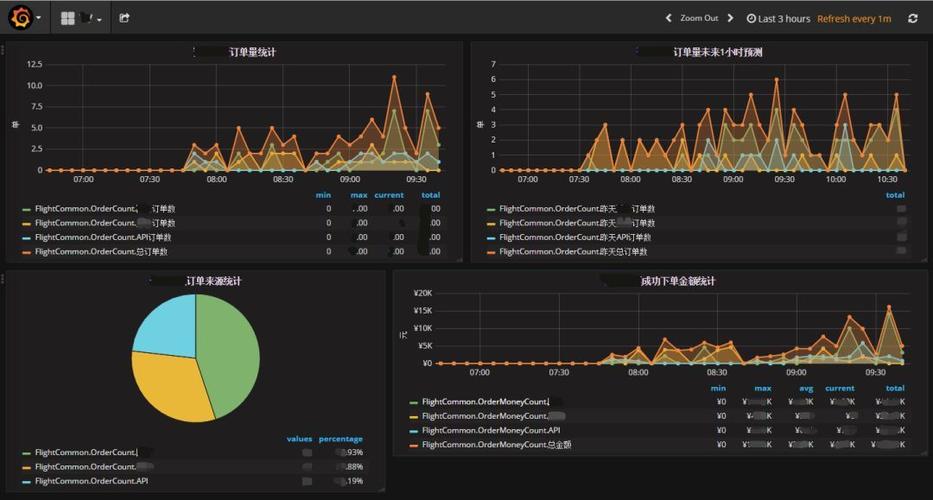

【nacos没有暴露出自身状态的metrics吗?】
在分布式系统中,监控是至关重要的一环,它可以帮助我们了解系统的运行状况、性能瓶颈以及故障情况等,而Metrics(指标)作为监控的核心,可以提供系统的各种度量数据,如CPU利用率、内存使用量、网络吞吐量等,对于Nacos来说,作为一个服务注册与发现组件,它同样需要监控系统的状态和性能,Nacos是否暴露了自身的状态的Metrics呢?
答案是肯定的,Nacos提供了一系列的Metrics,用于监控系统的各个方面,下面将详细介绍Nacos暴露出的Metrics内容。
1、服务注册与发现相关Metrics:
nacos_registry_total:表示Nacos中已注册的服务总数。
nacos_registry_success:表示成功注册到Nacos的服务数量。
nacos_registry_failure:表示注册失败的服务数量。
nacos_registry_get_all_services_latency:表示获取所有服务列表的延迟时间。
nacos_registry_get_service_latency:表示获取单个服务信息的延迟时间。
nacos_registry_get_instances_latency:表示获取服务实例列表的延迟时间。

nacos_registry_heartbeat_total:表示Nacos接收到的服务心跳总数。
nacos_registry_heartbeat_success:表示成功处理的服务心跳数量。
nacos_registry_heartbeat_failure:表示处理失败的服务心跳数量。
2、配置管理相关Metrics:
nacos_config_total:表示Nacos中已创建的配置总数。
nacos_config_success:表示成功创建的配置数量。
nacos_config_failure:表示创建配置失败的数量。
nacos_config_get_all_configs_latency:表示获取所有配置列表的延迟时间。
nacos_config_get_config_latency:表示获取单个配置信息的延迟时间。
nacos_config_listener_total:表示监听配置变更的客户端总数。
nacos_config_listener_success:表示成功接收到配置变更通知的客户端数量。
nacos_config_listener_failure:表示接收配置变更通知失败的客户端数量。
3、集群管理相关Metrics:
nacos_cluster_total:表示Nacos中的节点总数。
nacos_cluster_healthy:表示健康状态的节点数量。
nacos_cluster_unhealthy:表示不健康状态的节点数量。
nacos_cluster_election:表示进行领导者选举的次数。
nacos_cluster_elected:表示成功选举为领导者的次数。
nacos_cluster_election_timeout:表示选举超时的次数。
4、负载均衡相关Metrics:
nacos_loadbalancer_total:表示Nacos中的负载均衡器总数。
nacos_loadbalancer_success:表示成功处理的请求数量。
nacos_loadbalancer_failure:表示处理失败的请求数量。
nacos_loadbalancer_latency:表示请求的平均延迟时间。
通过以上Metrics,我们可以全面了解Nacos在服务注册与发现、配置管理和集群管理等方面的运行状况和性能表现,这些Metrics可以帮助我们及时发现问题并进行优化,保证系统的稳定运行和高效性能。
接下来,我将回答两个与本文相关的问题,并提供解答。
问题1:如何查看Nacos暴露出的Metrics?
答:要查看Nacos暴露出的Metrics,可以使用一些常用的监控工具或平台,如Prometheus、Grafana等,需要在Nacos上启用Metrics采集功能,并配置好相应的采集参数和存储方式(如InfluxDB、OpenTSDB等),通过监控工具连接到Nacos的Metrics存储端点,即可查看和分析Metrics数据,具体的操作步骤可以参考Nacos官方文档或相关教程。
问题2:如何利用Nacos暴露出的Metrics进行性能优化?
答:利用Nacos暴露出的Metrics进行性能优化可以从以下几个方面入手:
1、服务注册与发现方面:根据nacos_registry相关的Metrics,可以观察服务的注册成功率、注册失败率以及获取服务信息和实例列表的延迟情况等指标,从而判断是否存在注册瓶颈或性能问题,进而采取相应的优化措施,如增加注册并发数、优化注册流程等。
2、配置管理方面:通过nacos_config相关的Metrics,可以监测配置创建成功率、获取配置列表和单个配置信息的延迟情况等指标,以评估配置管理的性能表现,并根据需要进行优化,如增加配置存储容量、调整缓存策略等。
3、集群管理方面:根据nacos_cluster相关的Metrics,可以了解节点的健康状态、选举次数和选举结果等信息,以便及时发现和解决集群管理方面的问题,如增加健康检查频率、优化领导者选举算法等。
4、负载均衡方面:通过nacos_loadbalancer相关的Metrics,可以监测负载均衡器的请求处理成功率、延迟情况等指标,以评估负载均衡的性能表现,并根据需要进行优化,如调整负载均衡算法、增加负载均衡节点等。
通过充分利用Nacos暴露出的Metrics数据,结合对系统的实际需求和性能目标的分析,可以进行有针对性的性能优化工作,提升系统的稳定性和性能表现。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/463340.html
 微信扫一扫
微信扫一扫