



当调用机器翻译接口时,如果将源语言设置为"auto",系统会自动识别源语言,为了了解识别到的语种,我们需要了解一些关于自动语言识别(Automatic Language Recognition,简称ALR)的知识。
自动语言识别
自动语言识别是一种通过计算机程序自动判断文本所属语言的技术,它通常使用统计模型、机器学习算法或深度学习模型来实现,自动语言识别在机器翻译、语音识别、信息检索等领域有广泛应用。
统计模型
早期的自动语言识别系统主要基于统计模型,如ngram模型和隐马尔可夫模型(Hidden Markov Model,简称HMM),这些模型通过分析文本中的字符序列或词序列来预测文本的语言。
ngram模型
ngram模型是一种基于统计的语言模型,它假设一个文本中出现某个词的概率只与前面的n1个词有关,对于英语,bigram(2gram)模型可以表示为:P(w_i|w_1, w_2, ..., w_{i1}),即给定前i1个词的情况下,第i个词出现的概率。
隐马尔可夫模型
隐马尔可夫模型是一种概率图模型,用于描述一个含有隐含未知参数的马尔可夫过程,在语言识别中,HMM假设每个词的出现只与其前面的状态有关,而与其他词无关,通过训练数据学习状态转移概率和观测概率,HMM可以用于预测给定观测序列的隐藏状态序列。
机器学习算法
随着机器学习技术的发展,许多自动语言识别系统开始采用机器学习算法,如支持向量机(Support Vector Machine,简称SVM)、决策树、随机森林等,这些算法可以直接从原始特征中学习分类器,而无需手动设计特征。
深度学习模型
近年来,深度学习技术在自动语言识别领域取得了显著的成果,深度学习模型,如循环神经网络(Recurrent Neural Network,简称RNN)、长短时记忆网络(Long ShortTerm Memory,简称LSTM)和Transformer等,已经在多个国际竞赛中取得冠军,这些模型能够捕捉长距离依赖关系,并具有较强的表达能力。
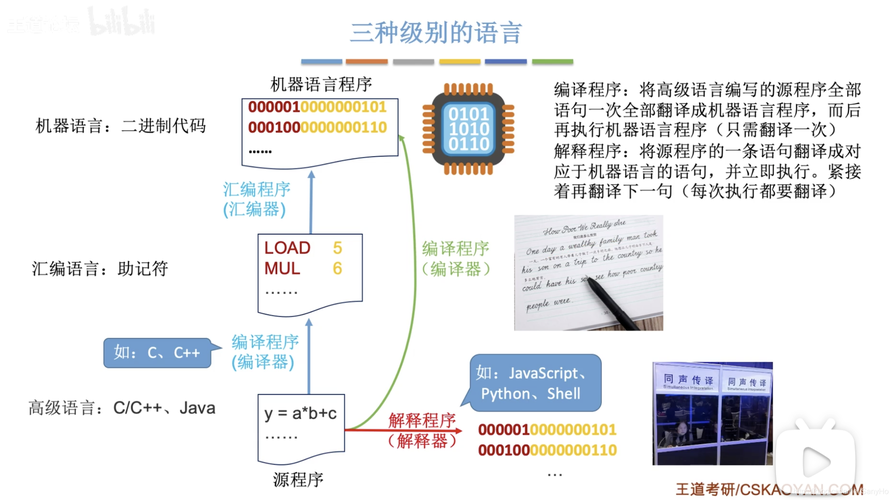
如何知道识别到的语种?
当调用机器翻译接口时,如果将源语言设置为"auto",系统会首先对输入文本进行自动语言识别,识别到的语种会作为参数传递给后续的机器翻译模块,为了获取识别到的语种,我们可以查看API返回的结果或日志信息。
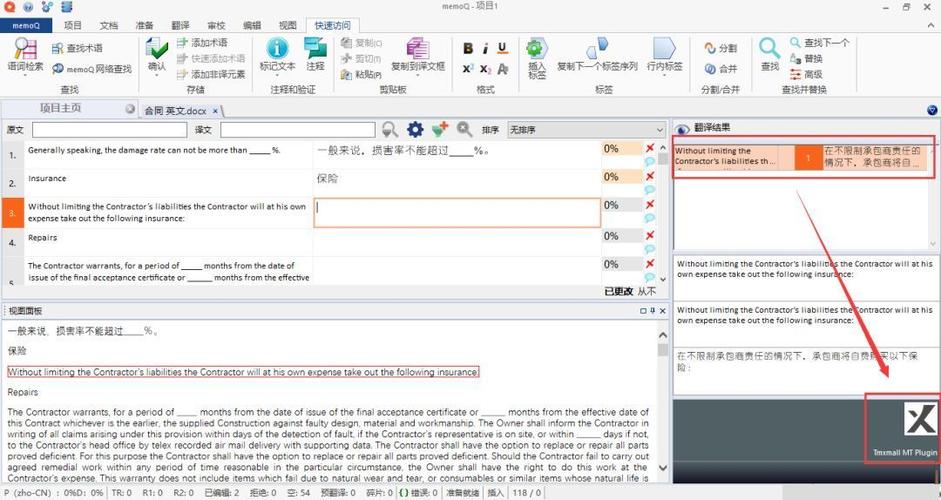
以谷歌翻译API为例,当调用translate方法时,它会返回一个包含翻译结果和元数据的响应对象,元数据中包含了识别到的源语言和目标语言,以下是一个Python示例:
from googletrans import Translator
translator = Translator()
result = translator.translate("Hello, world!", src="auto", dest="zh")
print(result.src) # 输出源语言:en
print(result.dest) # 输出目标语言:zh
与本文相关的问题及解答
问题1:为什么有时候自动语言识别的结果不准确?
答:自动语言识别的准确性受到多种因素的影响,如训练数据的质量和数量、特征的选择、模型的复杂度等,某些语言之间的相似性也可能导致误判,为了提高自动语言识别的准确性,可以尝试使用更多的训练数据、优化特征工程、调整模型参数等方法。
问题2:如何选择合适的自动语言识别模型?
答:选择合适的自动语言识别模型需要根据实际应用场景和需求来决定,统计模型和机器学习算法适用于较小的数据集和简单的任务;深度学习模型适用于较大的数据集和复杂的任务,在选择模型时,还需要考虑计算资源的限制、模型的训练和推理速度等因素。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/463894.html
 微信扫一扫
微信扫一扫