

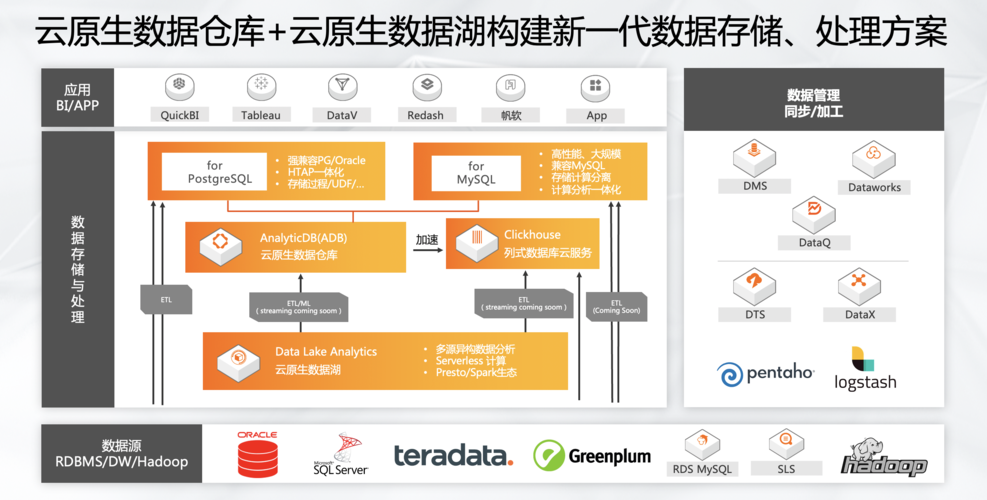

云数据仓库ADB(Amazon Data Warehouse)是亚马逊提供的一种云服务,用于存储、管理和分析大规模数据集,在本文中,我们将详细介绍如何设置30个分区的hot架构。
1. 什么是分区?
分区是数据仓库中的一个逻辑划分,它将数据按照某个特定的列进行分组,以提高查询性能和数据的管理效率,通过将数据分散到不同的分区中,可以减少查询时需要扫描的数据量,从而提高查询速度。
2. 为什么选择hot架构?
hot架构是一种常见的数据仓库架构,它使用一个或多个热节点来处理实时查询请求,并将结果缓存起来供后续查询使用,这种架构可以提高查询性能,减少对源数据的访问压力。
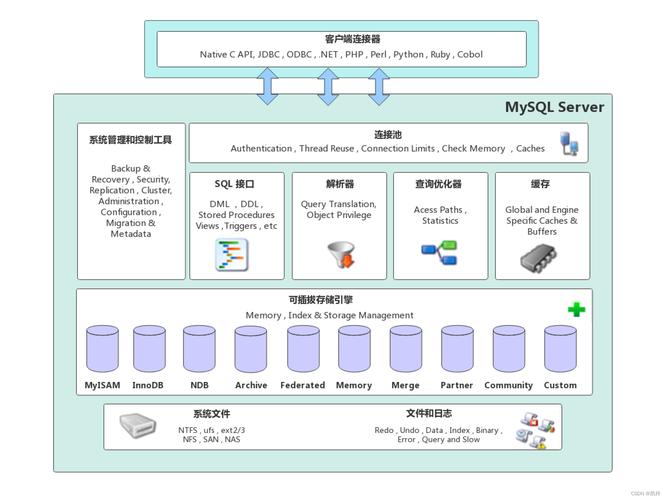
3. 设置30个分区的步骤
要设置30个分区,可以按照以下步骤进行操作:
3.1 创建表
在ADB中创建一个表,并定义好表的结构,假设我们要创建一个名为"sales"的表,包含以下列:product_id(产品ID)、sale_date(销售日期)、quantity(销售数量)。
CREATE TABLE sales (
product_id INT,
sale_date DATE,
quantity INT
);
3.2 添加分区键
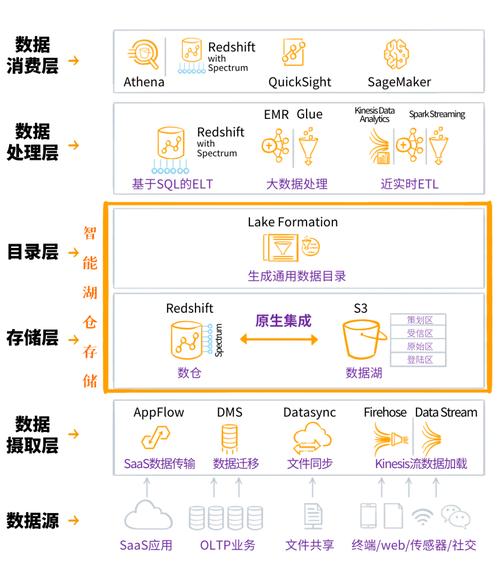
接下来,我们需要为表添加一个分区键,分区键是一个或多个列的组合,用于将数据分散到不同的分区中,在这个例子中,我们可以使用sale_date作为分区键。
ALTER TABLE sales ADD PARTITION (
PARTITION p0 VALUES LESS THAN ('20220101'),
PARTITION p1 VALUES LESS THAN ('20220201'),
...
PARTITION p29 VALUES LESS THAN (MAXVALUE)
);
在上面的代码中,我们使用了30个分区,每个分区对应一个月的销售数据,注意,最后一个分区p29包含了所有大于等于'20220101'且小于最大日期的数据。
3.3 加载数据
现在,我们可以开始向表中加载数据了,可以使用INSERT语句将数据插入到相应的分区中,要将某个产品的销售数据插入到p1分区中,可以使用以下语句:
INSERT INTO sales PARTITION (p1) VALUES (1, '20220115', 100);
3.4 创建热节点
为了提高查询性能,我们需要创建一个或多个热节点来处理实时查询请求,可以使用以下语句创建一个名为"hot_node"的热节点:
CREATE HOT NODE hot_node;
3.5 配置热节点缓存策略
为了提高查询性能,我们可以配置热节点的缓存策略,可以设置缓存大小、过期时间等参数,可以使用以下语句配置热节点的缓存策略:
ALTER HOT NODE hot_node CACHE (size = '10GB', expiration = '60');
在上面的代码中,我们设置了热节点的缓存大小为10GB,缓存过期时间为60秒,可以根据实际需求进行调整。
4. 总结
通过以上步骤,我们已经成功设置了30个分区的hot架构,这种架构可以提高查询性能,减少对源数据的访问压力,通过合理配置热节点的缓存策略,可以进一步提高查询效率。
与本文相关的问题及解答:
1、Q: 为什么要使用分区?
A: 使用分区可以将数据按照某个特定的列进行分组,以提高查询性能和数据的管理效率,通过将数据分散到不同的分区中,可以减少查询时需要扫描的数据量,从而提高查询速度。
2、Q: 为什么要选择hot架构?
A: hot架构是一种常见的数据仓库架构,它使用一个或多个热节点来处理实时查询请求,并将结果缓存起来供后续查询使用,这种架构可以提高查询性能,减少对源数据的访问压力。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/463950.html
 微信扫一扫
微信扫一扫