


在自然语言处理(NLP)领域,实体抽取和简历抽取是两个重要的任务,实体抽取是指从文本中识别并提取出预定义的实体,如人名、地名、组织机构等,而简历抽取则是指从简历文本中提取关键信息,如教育背景、工作经历、技能特长等。
对于这两个任务,可以使用模型的原始能力进行处理,而无需进行微调训练,下面将详细介绍如何使用模型的原始能力进行实体抽取和简历抽取。
1. 实体抽取
1.1 数据预处理
在进行实体抽取之前,首先需要对文本进行预处理,包括分词、去除停用词、词性标注等操作,这些预处理步骤可以帮助模型更好地理解文本的语义。
1.2 特征提取
接下来,需要从预处理后的文本中提取特征,常用的特征提取方法包括词袋模型(Bag of Words)、TFIDF、Word2Vec等,这些方法可以将文本转化为计算机可以理解的向量表示。
1.3 模型选择
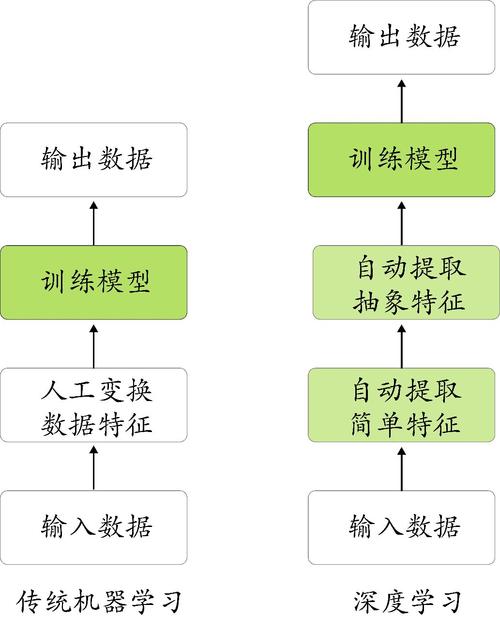
根据任务的需求,可以选择不同的模型进行实体抽取,常见的模型包括基于规则的方法、基于统计的方法和基于深度学习的方法,基于深度学习的方法通常具有更好的性能。
1.4 模型训练

使用标注好的数据集对选择的模型进行训练,训练过程中,模型会学习到如何从文本中识别和提取实体的能力。
1.5 模型评估
训练完成后,需要对模型进行评估,以了解其在实体抽取任务上的性能,常用的评估指标包括准确率、召回率、F1值等。
2. 简历抽取
2.1 数据预处理
简历抽取也需要对文本进行预处理,包括分词、去除停用词、词性标注等操作,这些预处理步骤可以帮助模型更好地理解文本的语义。
2.2 特征提取
与实体抽取类似,简历抽取也需要从预处理后的文本中提取特征,常用的特征提取方法包括词袋模型(Bag of Words)、TFIDF、Word2Vec等,这些方法可以将文本转化为计算机可以理解的向量表示。
2.3 模型选择
根据任务的需求,可以选择不同的模型进行简历抽取,常见的模型包括基于规则的方法、基于统计的方法和基于深度学习的方法,基于深度学习的方法通常具有更好的性能。
2.4 模型训练
使用标注好的数据集对选择的模型进行训练,训练过程中,模型会学习到如何从简历文本中提取关键信息的能力。
2.5 模型评估
训练完成后,需要对模型进行评估,以了解其在简历抽取任务上的性能,常用的评估指标包括准确率、召回率、F1值等。
结论
通过以上介绍,可以看出实体抽取和简历抽取可以使用模型的原始能力进行处理,而无需进行微调训练,只需要选择合适的模型和特征提取方法,并进行适当的数据预处理和模型训练,就可以实现这两个任务的目标。
相关的问题和解答:
1、问题:为什么不需要对模型进行微调训练?
解答:实体抽取和简历抽取是常见的NLP任务,已经有很多公开可用的预训练模型可以直接用于这些任务,这些预训练模型在大规模的语料库上进行了训练,已经学习到了丰富的语义信息,可以直接使用这些预训练模型的原始能力进行实体抽取和简历抽取,而无需进行微调训练,微调训练通常适用于特定领域的任务,而在通用任务上使用预训练模型已经可以取得很好的效果。
2、问题:如何处理未标注的数据?
解答:在实体抽取和简历抽取中,如果只有少量的标注数据可用,可以考虑使用半监督学习或无监督学习方法来处理未标注的数据,半监督学习可以利用少量标注数据和大量未标注数据进行训练,提高模型的性能,无监督学习方法可以从未标注的数据中自动学习到有用的信息,例如聚类、主题建模等方法,还可以考虑使用迁移学习的方法,将在一个领域上训练好的模型迁移到另一个领域上进行处理,这样可以充分利用已有的数据和知识,提高模型的性能。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/464305.html
 微信扫一扫
微信扫一扫