

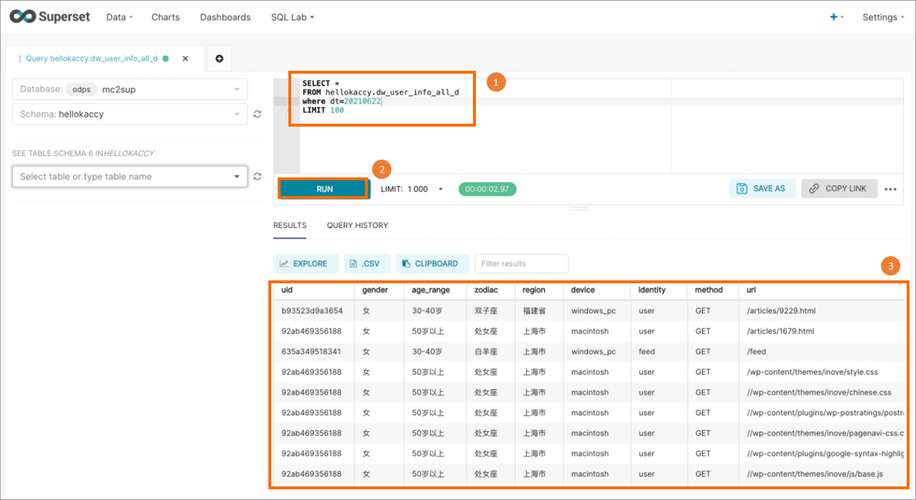
在DataWorks中查询Polardb的数据,需要进行以下步骤:
1、创建数据源:在DataWorks中创建一个Polardb的数据源,点击左侧导航栏的“数据源”,然后点击右上角的“新建”按钮,在弹出的对话框中,选择“数据库”,并填写相应的连接信息,如主机地址、端口号、用户名和密码等,点击“测试连接”按钮,确保连接成功,点击“确定”按钮完成数据源的创建。
2、创建数据集:接下来,在DataWorks中创建一个Polardb的数据集,点击左侧导航栏的“数据集”,然后点击右上角的“新建”按钮,在弹出的对话框中,选择刚刚创建的Polardb数据源,并填写相应的表名或SQL语句,点击“预览”按钮,可以查看数据集的内容,点击“确定”按钮完成数据集的创建。
3、创建作业:现在,可以在DataWorks中创建一个作业来查询Polardb的数据,点击左侧导航栏的“作业”,然后点击右上角的“新建”按钮,在弹出的对话框中,选择刚刚创建的数据集作为输入数据源,并设置相应的处理逻辑和输出结果,可以使用SQL语句或其他数据处理工具来查询和分析数据,点击“确定”按钮完成作业的创建。
4、运行作业:完成作业的创建后,可以点击作业名称进入作业详情页面,在作业详情页面,可以设置作业的执行计划和调度方式,可以选择立即执行作业,也可以设置定时任务来定期执行作业,点击“运行”按钮,作业将开始执行,并在执行完成后生成相应的结果。
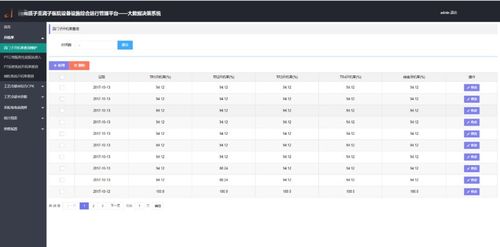
5、查看结果:作业执行完成后,可以在DataWorks中查看查询到的Polardb数据的结果,点击左侧导航栏的“结果”,可以看到所有已执行的作业及其对应的结果,点击某个作业的结果,可以查看详细的查询结果和数据分析报告,可以根据需要对结果进行进一步的处理和展示。
通过以上步骤,在DataWorks中可以方便地查询到Polardb的数据,下面提出两个与本文相关的问题,并进行解答:
问题1:如何在DataWorks中配置Polardb的数据源?
答:在DataWorks中配置Polardb的数据源,需要点击左侧导航栏的“数据源”,然后点击右上角的“新建”按钮,在弹出的对话框中,选择“数据库”,并填写相应的连接信息,如主机地址、端口号、用户名和密码等,点击“测试连接”按钮,确保连接成功,点击“确定”按钮完成数据源的创建。
问题2:如何在DataWorks中创建Polardb的数据集?
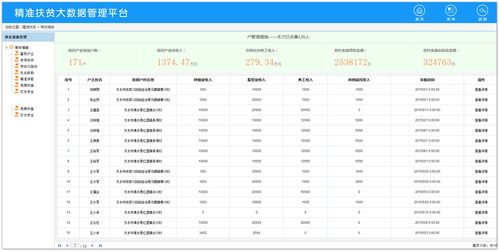
答:在DataWorks中创建Polardb的数据集,需要点击左侧导航栏的“数据集”,然后点击右上角的“新建”按钮,在弹出的对话框中,选择刚刚创建的Polardb数据源,并填写相应的表名或SQL语句,点击“预览”按钮,可以查看数据集的内容,点击“确定”按钮完成数据集的创建。
通过在DataWorks中创建Polardb的数据源、数据集和作业,可以方便地查询和分析Polardb的数据,通过配置数据源、创建数据集和设置作业的处理逻辑和调度方式,可以实现对Polardb数据的灵活查询和分析,可以通过查看作业的结果来获取查询到的数据和分析结果。
问题3:如何在DataWorks中设置Polardb数据的定时任务?
答:在DataWorks中设置Polardb数据的定时任务,需要在作业详情页面进行设置,在作业详情页面,可以设置作业的执行计划和调度方式,可以选择立即执行作业,也可以设置定时任务来定期执行作业,点击“调度”选项卡,可以设置定时任务的时间间隔、执行时间和重复次数等参数,根据需要选择合适的时间间隔和执行时间,并设置重复次数来定期执行作业,点击“保存”按钮完成定时任务的设置。
问题4:如何在DataWorks中查看Polardb数据的查询结果?
答:在DataWorks中查看Polardb数据的查询结果,需要点击左侧导航栏的“结果”,可以看到所有已执行的作业及其对应的结果,点击某个作业的结果,可以查看详细的查询结果和数据分析报告,可以根据需要对结果进行进一步的处理和展示,如果需要导出查询结果,可以选择导出为CSV文件或其他格式的文件进行保存和使用。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/464711.html
 微信扫一扫
微信扫一扫 