


【大数据计算MaxCompute开发环境能否设置首次全量周期性增量的数据同步任务呢?】
在大数据计算中,数据同步是一个重要的环节,MaxCompute作为阿里云提供的大数据计算服务,提供了强大的数据同步功能,本文将详细介绍如何在MaxCompute开发环境中设置首次全量周期性增量的数据同步任务。
1. 首次全量数据同步
首次全量数据同步是指在数据同步任务开始时,将源端数据库中的所有数据一次性同步到目标端MaxCompute中,这样可以确保目标端拥有完整的数据副本,为后续的增量同步打下基础。
1.1 创建同步作业
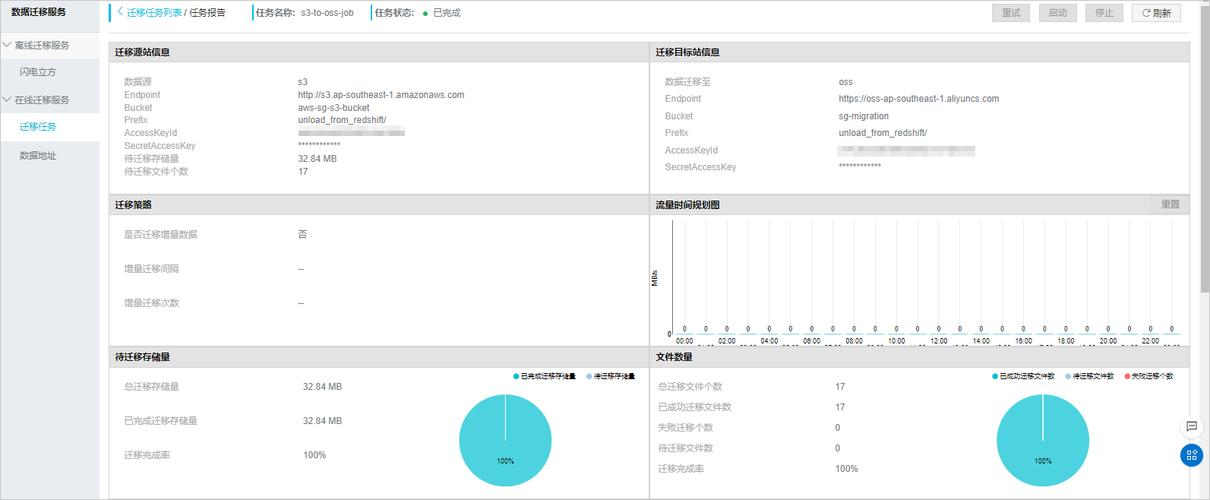
在MaxCompute控制台中,选择"数据同步",然后点击"新建同步作业"按钮,在弹出的对话框中,填写相关信息,包括源端数据库类型、目标端MaxCompute项目等。
1.2 配置源端和目标端信息
在同步作业的配置页面,需要填写源端数据库的连接信息和目标端MaxCompute项目的路径,源端数据库可以是关系型数据库(如MySQL、Oracle等)或非关系型数据库(如MongoDB、Redis等)。
1.3 设置同步策略
在同步作业的配置页面,可以选择同步策略为"首次全量",这样,在同步任务开始时,会将源端数据库中的所有数据一次性同步到目标端MaxCompute中。

1.4 启动同步作业
完成以上配置后,点击"保存并启动"按钮,即可启动首次全量数据同步任务,在同步过程中,可以通过日志查看同步进度和结果。
2. 周期性增量数据同步
周期性增量数据同步是指在首次全量同步完成后,按照一定的时间间隔,将源端数据库中新增或更新的数据同步到目标端MaxCompute中,这样可以保持目标端数据的实时性,避免数据延迟。
2.1 创建同步作业
在MaxCompute控制台中,选择"数据同步",然后点击"新建同步作业"按钮,在弹出的对话框中,填写相关信息,包括源端数据库类型、目标端MaxCompute项目等。
2.2 配置源端和目标端信息
在同步作业的配置页面,需要填写源端数据库的连接信息和目标端MaxCompute项目的路径,源端数据库可以是关系型数据库(如MySQL、Oracle等)或非关系型数据库(如MongoDB、Redis等)。
2.3 设置同步策略
在同步作业的配置页面,可以选择同步策略为"周期性增量",这样,在首次全量同步完成后,会按照指定的时间间隔,将源端数据库中新增或更新的数据同步到目标端MaxCompute中。
2.4 配置时间间隔和过滤条件
在同步策略的配置页面,可以设置时间间隔和过滤条件,时间间隔用于指定每次增量同步的时间间隔,过滤条件用于指定只同步满足特定条件的新增或更新数据。
2.5 启动同步作业
完成以上配置后,点击"保存并启动"按钮,即可启动周期性增量数据同步任务,在同步过程中,可以通过日志查看同步进度和结果。
与本文相关的问题及解答:
问题1:如何查看已创建的同步作业的状态和结果?
答:在MaxCompute控制台中,选择"数据同步",可以看到已创建的同步作业列表,点击某个同步作业的名称,可以进入该作业的详情页面,查看其状态、结果和日志等信息。
问题2:如何处理同步作业中的异常情况?
答:在同步作业的详情页面,可以查看其日志信息,如果发现异常情况,可以根据日志中的提示进行排查和处理,如果无法解决,可以联系MaxCompute技术支持获取帮助。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/464965.html
 微信扫一扫
微信扫一扫