

PaddlePaddle支持模型压缩与存储优化,包括量化、剪枝、蒸馏等技术,降低模型大小和计算复杂度。
模型压缩
1、剪枝(Pruning)
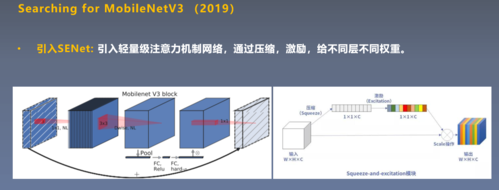

定义:通过移除神经网络中的冗余连接或权重,减少模型的大小和计算量。
方法:全局剪枝、结构化剪枝、量化剪枝等。
优点:减小模型大小、加速推理速度、降低内存占用。
缺点:可能影响模型性能。
2、量化(Quantization)
定义:将浮点数权重和激活值转换为低精度整数表示,减少模型的存储和计算需求。
方法:二值量化、静态量化、动态量化等。
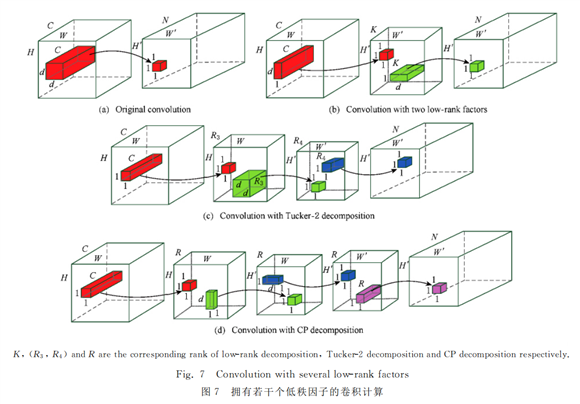
优点:减小模型大小、加速推理速度、降低内存占用。
缺点:可能引入量化误差,影响模型精度。
3、知识蒸馏(Knowledge Distillation)
定义:将大模型的知识迁移到小模型中,使小模型具有类似大模型的性能。
方法:教师学生网络结构、软目标训练等。
优点:减小模型大小、加速推理速度、降低内存占用。
缺点:需要训练额外的小模型。
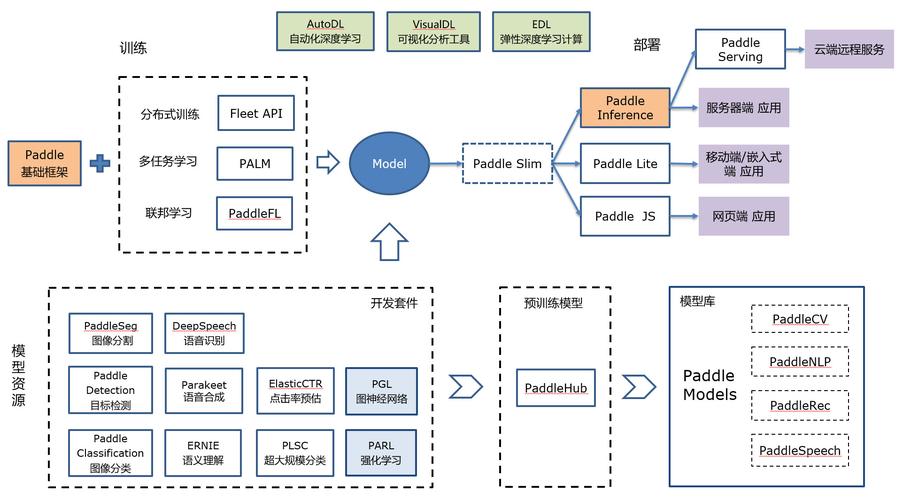
模型存储优化
1、模型压缩格式
PaddlePaddle支持多种模型压缩格式,如ONNX、TensorRT等,可以减小模型存储空间。
ONNX:一种开放的神经网络交换格式,可跨平台部署和优化。
TensorRT:由NVIDIA开发的高性能推理引擎,可用于加速深度学习模型的推理过程。
2、分布式存储
PaddlePaddle支持分布式存储方式,可以将大型模型分割存储在多个设备上,提高存储效率。
分布式训练:将模型参数和梯度分布在多个设备上进行训练,加快训练速度。
分布式推理:将模型部署在多个设备上进行推理,提高推理吞吐量。
相关问题与解答
问题1:如何选择合适的模型压缩方法?
解答:选择合适的模型压缩方法需要考虑多个因素,包括模型大小、计算资源限制、推理速度要求等,可以尝试不同的压缩方法,并通过实验评估其对模型性能的影响,选择最适合的方法。
问题2:如何平衡模型压缩与性能损失?
解答:在进行模型压缩时,需要权衡压缩比例和性能损失之间的关系,较大的压缩比例会导致较大的性能损失,可以通过调整压缩参数、使用更复杂的压缩算法等方式来平衡二者之间的关系,以达到最佳的压缩效果。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/480509.html
 微信扫一扫
微信扫一扫