

这是一个Flink中的窗口操作问题,window1是一个持续10秒的滚动窗口。
在 Apache Flink 中,窗口(Window)是一种用于处理无界和有界数据流的抽象概念,窗口将数据流中的元素分组,以便对每个分组执行某些操作,例如计算聚合函数,Flink 支持不同类型的窗口,包括基于时间的窗口、基于数量的窗口以及会话窗口等。
当你提到 "window1 是一个 10 秒的窗口" 时,这通常意味着你定义了一个基于时间的窗口,其长度为 10 秒,也就是说,这个窗口会接收到数据流中的元素,并将这些元素根据它们的时间戳分组成大小为 10 秒的批次,每过 10 秒,窗口就会 "滚动",新的窗口开始接收元素,而旧窗口则准备进行计算。

以下是一些关于连续两个窗口问题的详细讨论:
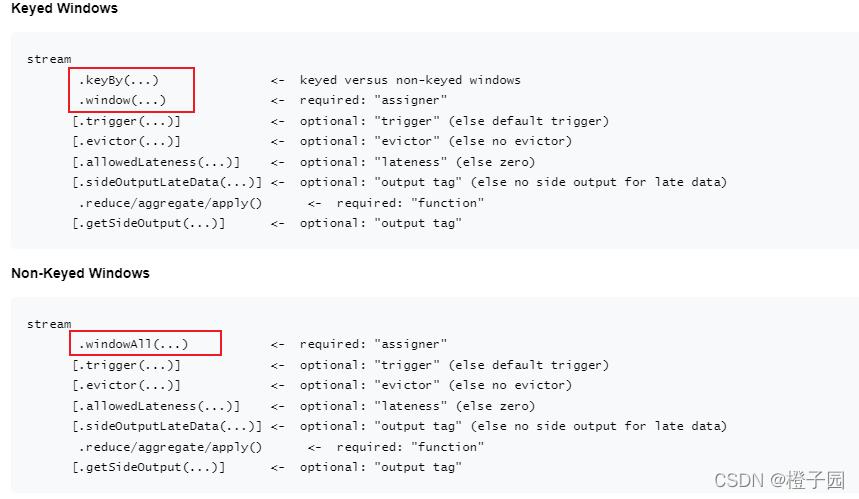
窗口类型
在 Flink 中,你可以使用不同的窗口类型来定义如何组织数据流中的元素,对于基于时间的窗口,有两种常见的类型:
1、滚动窗口(Tumbling Windows): 每个窗口包含固定时间间隔内的所有元素,窗口之间没有重叠。
2、滑动窗口(Sliding Windows): 每个窗口也是包含固定时间间隔内的元素,但是窗口之间可以有重叠。
窗口操作
在定义了窗口之后,你可以在窗口上执行各种操作,如计算聚合函数(例如计数、求和、平均值等)。
连续两个窗口的问题
如果你有两个连续的窗口,比如两个 10 秒的滚动窗口,那么第一个窗口会在时间 [0, 10) 内收集数据,第二个窗口会在时间 [10, 20) 内收集数据,这里的 [0, 10) 表示从时间 0 开始,但不包括时间 10,以此类推。
示例代码
以下是一个使用 Flink Java API 创建 10 秒滚动窗口并计算每个窗口内元素数量的简单示例:
import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.windowing.time.Time; import org.apache.flink.streaming.api.windowing.windows.TimeWindow; public class WindowExample { public static void main(String[] args) throws Exception { // 设置执行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // 创建数据流 DataStream<String> input = env.fromElements("a", "b", "c", "d", "e", "f"); // 定义 10 秒的滚动窗口 input .keyBy(value > value) .timeWindow(Time.seconds(10)) .sum(1); // 执行作业 env.execute("10 Seconds Tumbling Window Example"); } }
在这个例子中,我们首先设置了 Flink 的执行环境,然后创建了一个包含字符串元素的简单数据流,接下来,我们使用 keyBy 方法对元素进行分组(在这个例子中,我们简单地使用了元素自身的值作为键),然后定义了一个 10 秒的滚动窗口,我们使用 sum 方法计算每个窗口内的元素数量。
上文归纳
在 Flink 中,10 秒的窗口意味着你定义了一个时间范围为 10 秒的窗口,用于对数据流中的元素进行分组和处理,连续两个这样的窗口将分别处理时间 [0, 10) 和 [10, 20) 内到达的元素,通过窗口操作,你可以对每个窗口内的数据执行各种计算和分析。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/481298.html
 微信扫一扫
微信扫一扫