

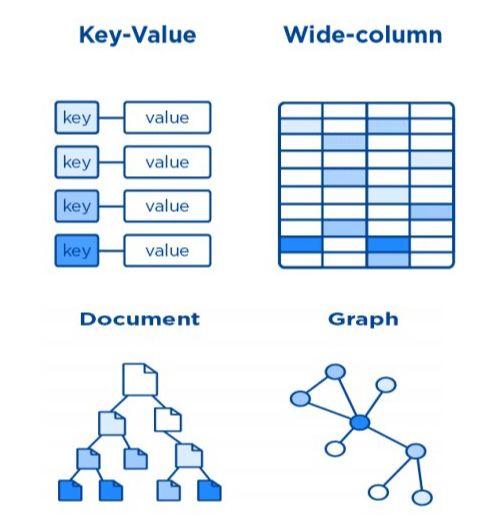
图数据库使用节点和边来存储数据,查询时通过遍历节点和边的关系实现。支持复杂的关系查询和分析。
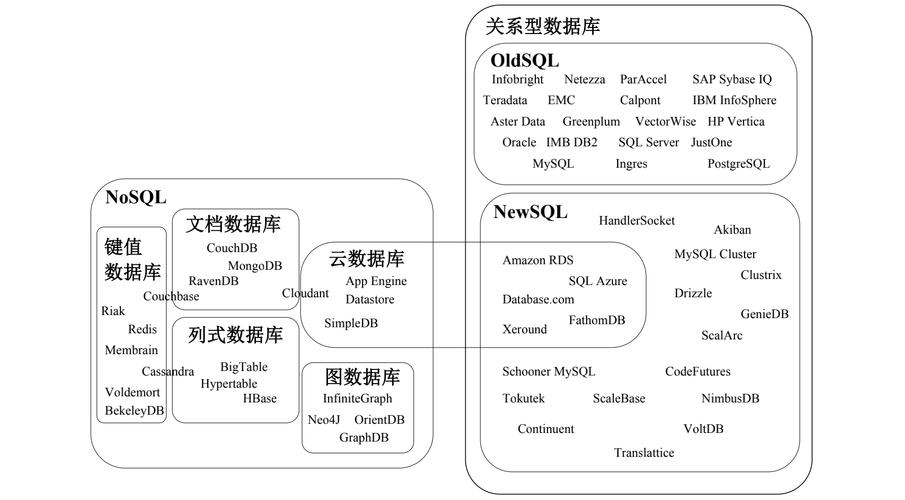
图数据库是一种专门用于存储和查询图形数据结构的数据库,在NoSQL中,图数据库通过使用节点、边和属性来表示图形数据,并提供高效的查询语言和算法来处理图形关系。
以下是关于图数据库存储和查询数据的详细解释:

1、存储数据:
节点(Node):图数据库中的每个实体都表示为一个节点,节点可以具有多个属性,例如姓名、年龄等。
边(Edge):边表示节点之间的关系,边可以具有方向性,也可以是无向的,边还可以具有权重,表示关系的重要性或成本。
属性(Property):节点和边都可以具有属性,用于描述其特征或附加信息。
2、存储方式:
邻接列表(Adjacency List):每个节点维护一个邻接列表,其中包含与该节点直接相连的其他节点的引用,这种方式适用于稀疏图。
邻接矩阵(Adjacency Matrix):使用二维数组表示图中的节点和边的关系,这种方式适用于稠密图。
3、查询数据:
广度优先搜索(BreadthFirst Search,BFS):从起始节点开始,逐层遍历图中的节点,直到找到目标节点或遍历完所有可达节点。
深度优先搜索(DepthFirst Search,DFS):从一个起始节点开始,沿着一条路径深入到尽可能深的节点,然后回溯并尝试其他路径。
最短路径(Shortest Path):计算两个节点之间的最短路径,可以使用Dijkstra算法或BellmanFord算法等。
连通分量(Connected Component):查找图中相互连通的节点集合,可以使用Tarjan算法或Kosaraju算法等。
4、查询语言:
Cypher:Neo4j图数据库使用的查询语言,类似于SQL,但专门用于图数据结构。
Gremlin:Apache TinkerPop图计算框架使用的查询语言,支持多种图数据库。
5、索引和优化:
为了提高查询性能,图数据库通常会对节点和边的属性进行索引,索引可以加速查询操作,特别是在大型图中。
图数据库还提供了一些优化技术,如缓存、分区和并行处理等,以提高查询效率和扩展性。
归纳起来,图数据库通过存储节点、边和属性来表示图形数据结构,并提供专门的查询语言和算法来处理图形关系,它们通常采用邻接列表或邻接矩阵等方式来存储数据,并提供各种查询操作和优化技术来满足不同的需求。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/484097.html
 微信扫一扫
微信扫一扫