

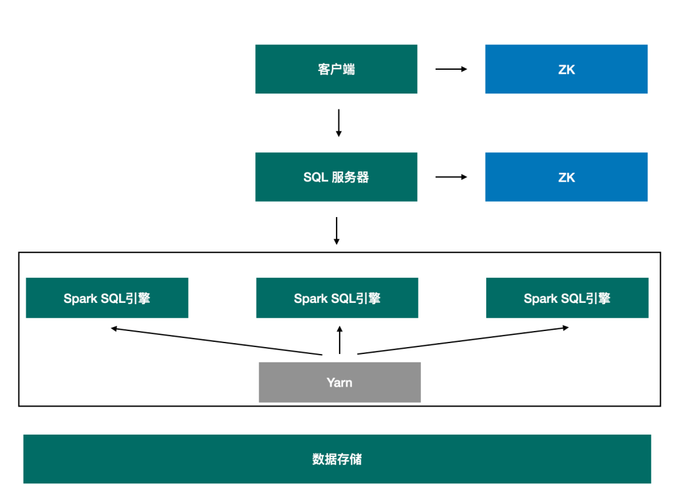
使用Spark的JDBC连接方式,将MySQL JDBC驱动包添加到Spark的classpath中,然后通过Spark SQL执行SQL语句即可连接MySQL数据库。
要使用Spark连接MySQL数据库,可以按照以下步骤进行操作:
1、导入所需的库和模块:

```python
from pyspark.sql import SparkSession
from pyspark.sql.functions import *
from pyspark.sql.types import *
```
2、创建SparkSession对象:
```python
spark = SparkSession.builder
.appName("Spark MySQL Connector")
.getOrCreate()
```
3、定义MySQL数据库的连接参数:
url: MySQL数据库的JDBC连接URL,格式为jdbc:mysql://<hostname>:<port>/<database>。
properties: 可选的连接属性,例如用户名、密码等,可以使用字典形式传递。

driver: MySQL的JDBC驱动程序类名,默认为com.mysql.jdbc.Driver。
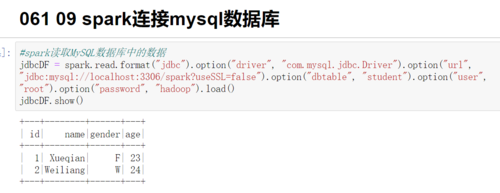
4、使用createDataFrame方法从MySQL数据库读取数据并创建DataFrame:
```python
df = spark.read
.format("jdbc")
.option("url", "jdbc:mysql://<hostname>:<port>/<database>")
.option("properties", {"user": "<username>", "password": "<password>"})
.option("driver", "com.mysql.jdbc.Driver")
.load()
```
5、对DataFrame进行操作:
可以使用Spark SQL对DataFrame进行各种操作,例如查询、过滤、聚合等,以下是一些示例操作:
```python
# 显示前10行数据
df.show(10)
# 执行SQL查询语句
df.createOrReplaceTempView("my_table")
result = spark.sql("SELECT * FROM my_table WHERE column_name = 'value'")
result.show()
# 添加新列并进行计算
df = df.withColumn("new_column", col("column1") + col("column2"))
df.show()
```
6、关闭SparkSession:
在完成所有操作后,记得关闭SparkSession以释放资源:
```python
spark.stop()
```
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/485127.html
 微信扫一扫
微信扫一扫