

$bucket聚合阶段将数据分成多个桶,并对每个桶中的数据进行统计和计算,以实现数据的分组和分析。
MongoDB中的$bucket聚合阶段用于将数据分成多个桶(bucket),并对每个桶中的数据进行统计和计算,它可以根据指定的字段值的范围将文档分组,并对每个组应用累计函数,如求和、平均值等。
以下是关于$bucket聚合阶段的详细解释:
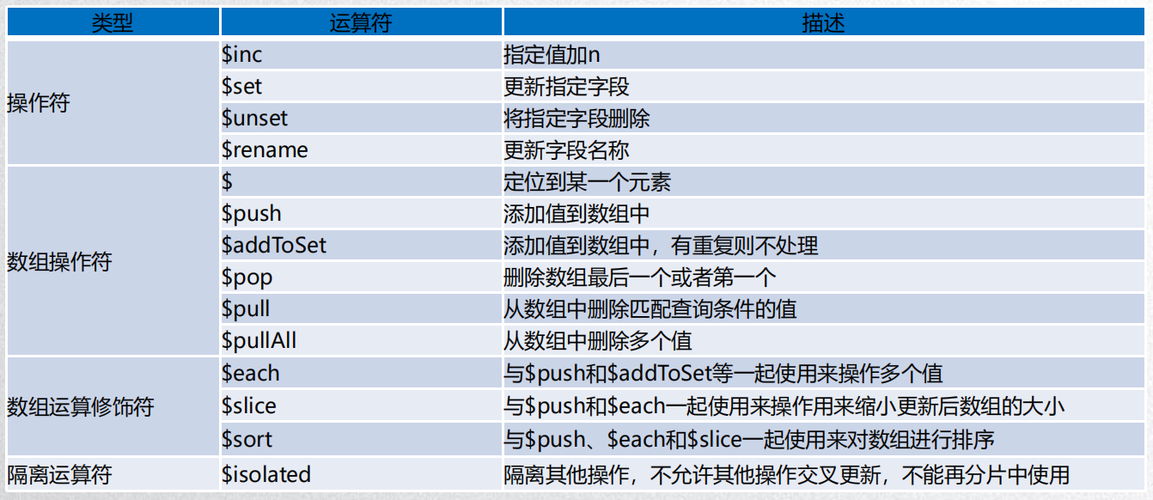

1、作用:
数据分组:根据指定字段的值将文档分成多个桶。
数据统计:对每个桶中的数据进行统计和计算。
结果输出:返回包含桶信息和统计数据的结果集。
2、语法:
```
{
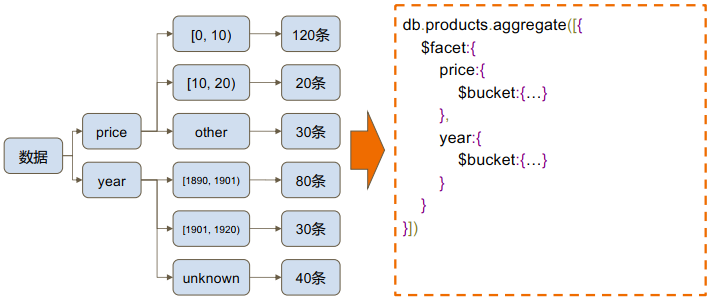
$bucket: {
groupBy: <字段名>,
boundaries: [ <边界1>, <边界2>, ... ],
default: <默认值>,
output: {
"<输出字段名1>": { <累计函数1>: "<表达式1>" },
"<输出字段名2>": { <累计函数2>: "<表达式2>" },
...
}
}
}
```
3、参数说明:
groupBy:指定用于分组的字段名。
boundaries:定义桶的边界值数组,文档的指定字段值在这个数组范围内的将被分到同一个桶中。
default:当文档的指定字段值不在边界值数组中时,指定一个默认值作为该文档所属的桶。
output:定义输出结果集中的字段和对应的累计函数及表达式,可以自定义输出字段名和计算方式。
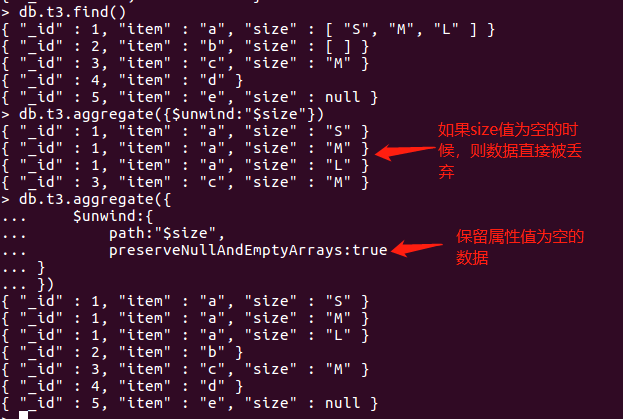
4、示例:
假设有一个名为"orders"的集合,其中包含订单信息,包括订单金额(amount)和订单日期(date)两个字段,我们想要按照订单金额的范围将订单分组,并计算每个范围内的订单总金额和平均金额,可以使用以下聚合查询实现:
```javascript
[
{
$bucket: {
groupBy: "$amount",
boundaries: [0, 100, 200, 300, 400, 500],
default: "其他",
output: {
"总金额": { $sum: "$amount" },
"平均金额": { $avg: "$amount" }
}
}
}
]
```
上述查询将按照订单金额的范围将订单分为五个桶,分别为小于100、100到200、200到300、300到400和大于等于400,对于不在边界值数组中的订单,将其归为"其他"桶,输出结果集中包含每个桶的总金额和平均金额。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/495368.html
 微信扫一扫
微信扫一扫