

Hadoop负载均衡算法通过将数据块分散存储在集群中的不同节点上,实现任务调度的公平性和高效性。
Hadoop负载均衡算法的实现可以通过以下步骤来完成:
1、数据分发:
Hadoop集群中的每个DataNode会周期性地向NameNode发送心跳信号,以报告其存储的数据块信息。
NameNode接收到心跳信号后,将数据块的映射关系存储在内存中,并维护一个文件系统目录树。
当客户端发起读写请求时,NameNode会根据文件系统的目录树来确定数据块的位置。
2、块分配策略:
Hadoop默认使用一种称为“机架感知”的块分配策略,该策略将数据块尽量分配到与客户端所在机架不同的其他机架上,以实现数据的分布式存储和负载均衡。
为了确定数据块所在的机架,Hadoop使用了机架识别码(Rack ID),每个DataNode在启动时会向NameNode发送自己的机架识别码。
NameNode根据数据块的大小和副本数来确定需要分配的DataNode数量,然后选择尽量分布在不同机架上的DataNode来存储数据块的副本。
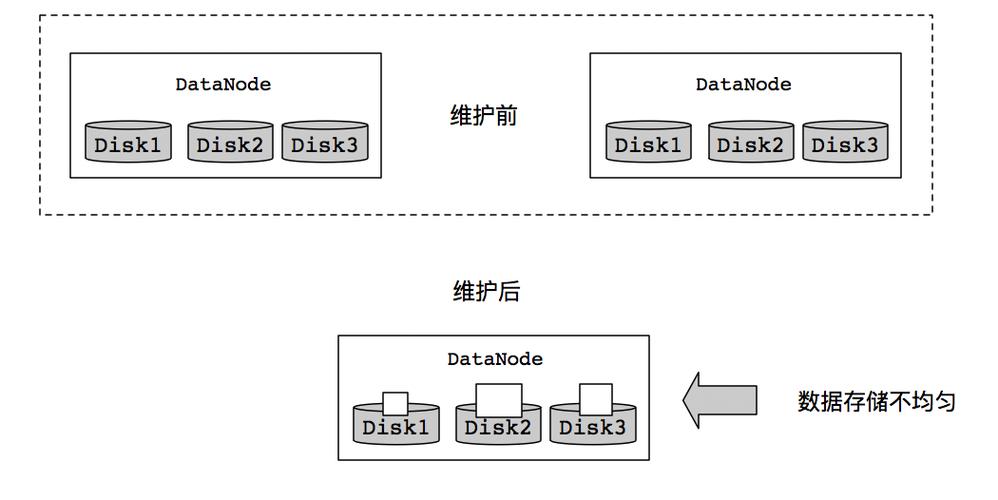
3、块副本放置:
Hadoop默认将每个数据块的副本放置在不同的DataNode上,以实现数据的冗余备份和容错性。
当第一个副本被写入某个DataNode后,第二个副本会被写入另一个DataNode,第三个副本会被写入第三个不同的DataNode,以此类推。
如果某个DataNode发生故障或宕机,Hadoop会自动将该节点上的数据块副本迁移到其他健康的DataNode上,以保证数据的可用性和可靠性。
4、数据读取:
当客户端发起读请求时,NameNode会返回包含目标数据块的所有DataNode列表。
客户端根据NameNode返回的DataNode列表中的数据块位置信息,并行地从多个DataNode上读取数据块的内容。
客户端最后将各个DataNode上读取到的数据块内容合并成最终的结果。
相关问题与解答:
问题1:Hadoop如何实现数据的容错性?
答:Hadoop通过将每个数据块的多个副本分布在不同的DataNode上来实现数据的容错性,当某个DataNode发生故障或宕机时,Hadoop会自动将该节点上的数据块副本迁移到其他健康的DataNode上,以保证数据的可用性和可靠性。
问题2:Hadoop的负载均衡算法是否支持动态调整副本数量?
答:是的,Hadoop的负载均衡算法支持动态调整副本数量,当某个DataNode上的负载过高或过低时,Hadoop可以根据实际需求动态增加或减少该节点上的数据块副本数量,以达到更好的负载均衡效果。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/500004.html
 微信扫一扫
微信扫一扫 