

在SQL中,可以使用
GROUP BY和HAVING子句来求出现重复次数的数据。以下是一个示例:,,``sql,SELECT column_name, COUNT(*) as count,FROM table_name,GROUP BY column_name,HAVING COUNT(*) > 1;,``
在SQL中,可以使用以下方法来找出出现重复次数的数据:
1、使用GROUP BY子句和HAVING子句结合COUNT()函数。
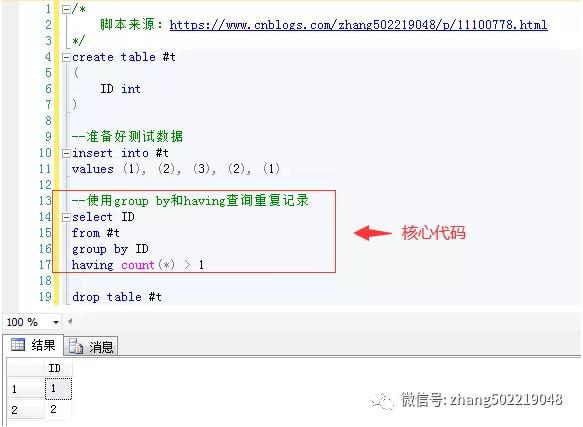

解析:我们需要对数据进行分组,然后计算每个分组的记录数,接着,我们可以通过HAVING子句筛选出记录数大于1的分组,即出现重复的数据。
代码示例:
SELECT column_name, COUNT(*) as count FROM table_name GROUP BY column_name HAVING count > 1;
2、使用JOIN和GROUP BY子句结合COUNT()函数。
解析:我们需要将原始表与自身进行连接,然后对连接后的表进行分组,计算每个分组的记录数,接着,我们可以通过WHERE子句筛选出记录数大于1的分组,即出现重复的数据。
代码示例:
SELECT t1.column_name, COUNT(*) as count FROM table_name t1 JOIN table_name t2 ON t1.column_name = t2.column_name GROUP BY t1.column_name HAVING count > 1;
3、使用DISTINCT关键字。
解析:我们可以先对数据进行去重,然后再计算每个分组的记录数,这样,我们就可以找出出现重复次数的数据。
代码示例:
SELECT column_name, COUNT(*) as count
FROM (
SELECT DISTINCT column_name
FROM table_name
) AS distinct_table
GROUP BY column_name
HAVING count > 1;

原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/500056.html
 微信扫一扫
微信扫一扫