

可以通过修改Hadoop配置文件hdfs-site.xml中的dfs.datanode.du.reserved属性来设置HDFS磁盘空间。
设置HDFS的磁盘空间可以通过以下步骤进行:
1、确定要设置的HDFS NameNode和DataNode节点。
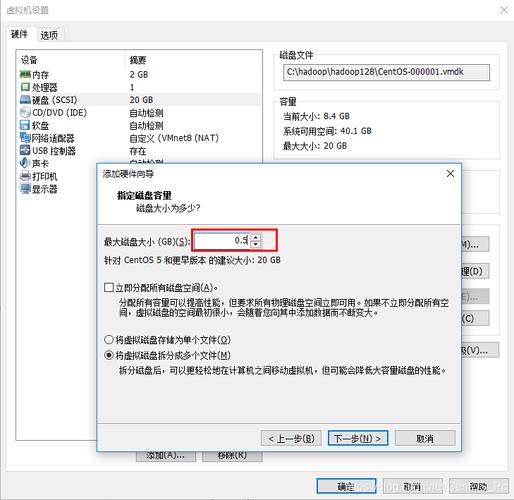

2、在每个节点上,找到Hadoop安装目录并进入etc/hadoop文件夹。
3、编辑hdfssite.xml文件,该文件包含了HDFS的配置信息。
4、在hdfssite.xml文件中,添加或修改以下配置项来设置磁盘空间:
```xml
<property>
<name>dfs.datanode.du.reserved</name>
<value>1073741824</value> <!预留给DataNode的数据存储空间,单位为字节 >
</property>
<property>
<name>dfs.datanode.fsdatasetcache.pinning.enabled</name>
<value>true</value> <!启用数据块缓存 >
</property>
<property>
<name>dfs.datanode.fsdatasetcache.pinning.targetSize</name>
<value>536870912</value> <!数据块缓存的目标大小,单位为字节 >
</property>
<property>
<name>dfs.datanode.fsdatasetcache.pinning.interval</name>
<value>604800</value> <!数据块缓存的清理间隔时间,单位为秒 >
</property>
```
5、根据实际需求,调整上述配置项的值,可以根据可用磁盘空间的大小来设置dfs.datanode.du.reserved的值。
6、保存并关闭hdfssite.xml文件。
7、重启HDFS集群中的NameNode和DataNode服务以使配置生效。
相关问题与解答:
问题1:如何查看当前HDFS的磁盘空间使用情况?
答:可以使用Hadoop提供的dfsadmin命令来查看HDFS的磁盘空间使用情况,运行以下命令可以获取详细的报告:
$ hdfs dfsadmin report
该命令将显示HDFS的总体使用情况、已用空间、剩余空间等信息。
问题2:如果需要增加HDFS的磁盘空间,应该如何操作?
答:如果需要增加HDFS的磁盘空间,可以按照以下步骤进行操作:
1、确认有足够的可用磁盘空间可供分配给HDFS。
2、在每个DataNode节点上,找到Hadoop安装目录并进入etc/hadoop文件夹。
3、编辑hdfssite.xml文件,添加或修改以下配置项来增加磁盘空间:
<property> <name>dfs.datanode.du.reserved</name> <value>新的预留空间大小</value> <!以字节为单位的新预留空间大小 > </property>
4、根据实际需求,调整上述配置项的值,确保新值大于当前的预留空间大小。
5、保存并关闭hdfssite.xml文件。
6、重启HDFS集群中的NameNode和DataNode服务以使配置生效。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/500293.html
 微信扫一扫
微信扫一扫