

SELECT DISTINCT 用于从表中选择不重复的记录,可以指定一个或多个列进行去重。
在SQL中,SELECT DISTINCT语句用于从表中选择唯一的不同值,它可以消除重复的行,只返回唯一的值。
使用SELECT DISTINCT的基本语法如下:


SELECT DISTINCT column1, column2, ... FROM table_name;
column1、column2等是要选择的唯一列名,table_name是表名。
下面是一个示例,展示如何使用SELECT DISTINCT:
假设我们有一个名为"employees"的表,包含以下列:id、name、age、department。
| id | name | age | department |
| 1 | John | 30 | Sales |
| 2 | Jane | 25 | Marketing |
| 3 | John | 30 | Sales |
| 4 | Alice | 28 | Engineering |
| 5 | Bob | 32 | Sales |
如果我们想要查询所有不同的部门名称,可以使用以下SQL语句:
SELECT DISTINCT department FROM employees;
执行结果将会是:
| department |
| Sales |
| Marketing |
| Engineering |
现在让我们来回答两个与本文相关的问题:
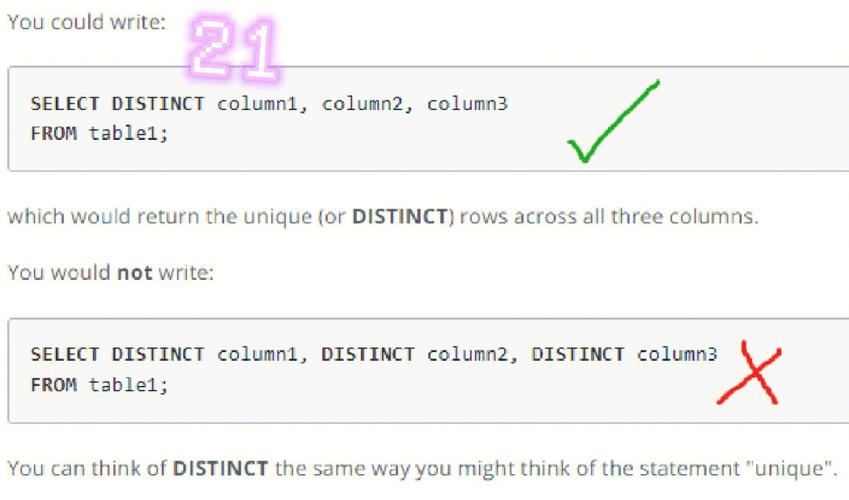
问题1:如何在SELECT DISTINCT中使用多个列?
解答:可以在SELECT DISTINCT后面列出多个列名,用逗号分隔开。SELECT DISTINCT column1, column2 FROM table_name;,这将返回所有唯一组合的列值。
问题2:如果表中没有重复值,是否还需要使用SELECT DISTINCT?
解答:即使表中没有重复值,也可以使用SELECT DISTINCT,在这种情况下,它仍然会返回原始表中的所有行,因为没有重复值需要去除,使用SELECT DISTINCT可以提高代码的可读性和一致性。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/502660.html
 微信扫一扫
微信扫一扫