

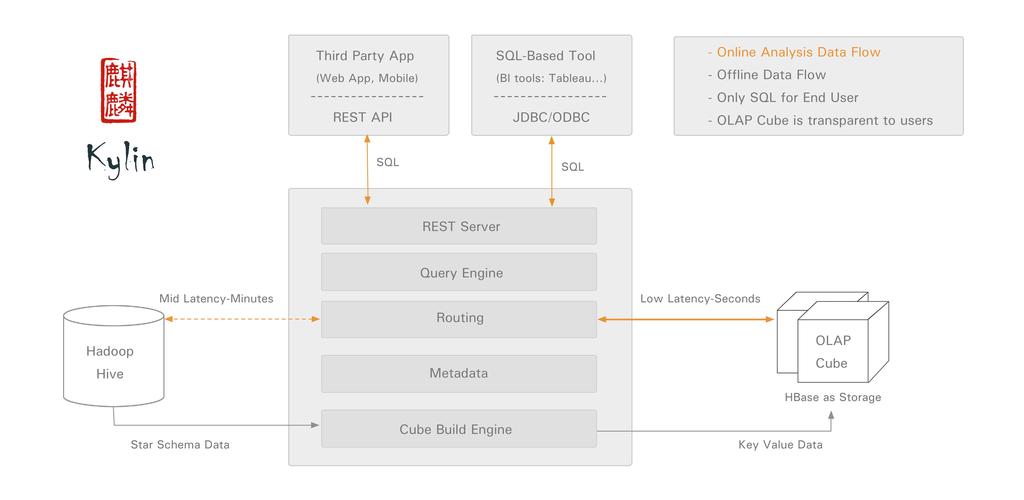
Kylin通过JDBC接口支持SQL查询,将SQL语句转换为Hadoop任务执行,并将结果返回给客户端。
Kylin是一个开源的分布式分析引擎,它支持SQL接口来查询大规模数据,下面是关于Kylin如何支持SQL接口的详细解释:
1、解析SQL语句:

Kylin通过ANTLR工具将输入的SQL语句解析成抽象语法树(AST)。
AST中包含了SQL语句的各个组成部分,如SELECT、FROM、WHERE等。
2、构建查询计划:
Kylin根据AST生成查询计划,该计划描述了如何从数据源中获取数据以及如何处理这些数据。
查询计划包括多个阶段,如数据源读取、映射转换、聚合计算等。
3、执行查询计划:
Kylin按照查询计划的顺序执行各个阶段的操作。
在数据源读取阶段,Kylin会连接到存储数据的Hadoop集群,并读取需要的数据。
在映射转换阶段,Kylin会对读取到的数据进行必要的转换和处理,以满足查询的需求。
在聚合计算阶段,Kylin会根据查询要求对数据进行聚合计算,并返回最终的结果。
4、返回结果:
Kylin将查询结果以SQL结果集的形式返回给用户。
结果集可以包含多列数据,每一列对应一个聚合指标或维度。
相关问题与解答:
问题1:Kylin支持哪些SQL语法?
答:Kylin支持大部分标准的SQL语法,包括SELECT、FROM、WHERE、GROUP BY、HAVING、ORDER BY等,由于Kylin是基于Hadoop的分布式计算引擎,因此一些特定的SQL语法可能不被支持或需要进行适当的修改。
问题2:Kylin如何优化SQL查询性能?
答:Kylin通过以下方式来优化SQL查询性能:
索引:Kylin支持为维度和度量创建索引,以提高查询速度。
Cube优化:Kylin会对预先计算好的Cube进行优化,以提高查询效率。
并行计算:Kylin可以利用Hadoop集群的并行计算能力,同时处理多个任务,从而提高查询速度。
压缩算法:Kylin使用压缩算法对数据进行压缩,减少数据传输和存储的开销。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/507458.html
 微信扫一扫
微信扫一扫