

Kylin支持多种存储后端,如Hadoop、Spark等,可通过配置文件进行配置。具体配置方式可参考官方文档。
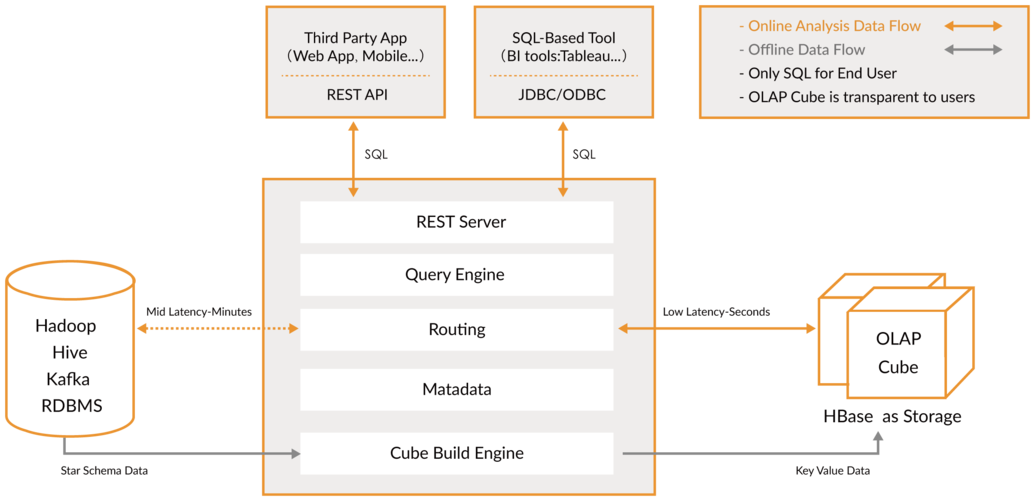
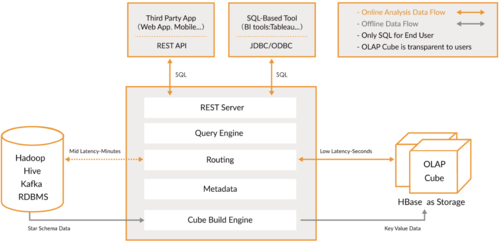
Kylin是一种开源的分布式分析引擎,支持多种存储后端,下面是关于如何配置Kylin多种存储后端的详细步骤:
1、配置Hadoop环境

确保已经安装和配置好Hadoop集群。
在Kylin的配置文件中设置Hadoop的相关参数,例如HDFS的地址、Zookeeper的地址等。
2、添加存储后端
在Kylin的配置文件中添加存储后端的配置信息。
Kylin支持多种存储后端,包括HBase、Hive、Kudu等,根据需要选择相应的存储后端进行配置。
3、HBase存储后端配置
在Kylin的配置文件中添加HBase的相关配置信息,包括HBase的连接地址、用户名、密码等。
配置HBase的表和列族的信息,用于存储Kylin的结果数据。
4、Hive存储后端配置
在Kylin的配置文件中添加Hive的相关配置信息,包括Hive的连接地址、用户名、密码等。
配置Hive的表和分区的信息,用于存储Kylin的结果数据。
5、Kudu存储后端配置
在Kylin的配置文件中添加Kudu的相关配置信息,包括Kudu的连接地址、用户名、密码等。
配置Kudu的表和列族的信息,用于存储Kylin的结果数据。
6、保存配置文件并重启Kylin服务
保存对配置文件的修改,并重新启动Kylin服务以使更改生效。
相关问题与解答:
问题1:如何在Kylin中使用多个存储后端?
解答:在Kylin中可以使用多个存储后端,每个存储后端可以用于不同的场景或需求,首先需要在Kylin的配置文件中添加各个存储后端的配置信息,然后根据需要选择合适的存储后端来存储Kylin的结果数据,可以在查询时指定使用特定的存储后端,也可以根据需要动态切换存储后端。
问题2:如何将Kylin的结果数据从Hive迁移到Kudu?
解答:要将Kylin的结果数据从Hive迁移到Kudu,可以按照以下步骤进行操作:
1. 创建Kudu表并定义列族和列的模式,与Hive表中的数据结构保持一致。
2. 编写一个脚本或程序,将Hive表中的数据导出到CSV格式的文件。
3. 使用Kudu的命令行工具或API,将CSV文件导入到Kudu表中。
4. 修改Kylin的配置文件,将存储后端从Hive切换为Kudu。
5. 重启Kylin服务,使更改生效。
通过以上步骤,可以将Kylin的结果数据从Hive迁移到Kudu,并在Kylin中使用Kudu作为新的存储后端。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/507462.html
 微信扫一扫
微信扫一扫