

使用DISTINCT关键字可以删除重复数据,或者使用GROUP BY和HAVING子句结合进行删除。
在SQL中删除重复数据的方法有以下几种:
1、使用DISTINCT关键字
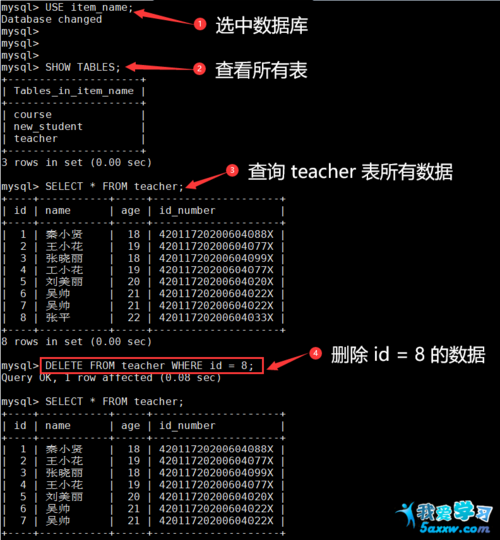

SELECT DISTINCT column_name FROM table_name;
这个查询语句会返回唯一的不重复值,但不会删除重复的数据。
2、使用GROUP BY和HAVING子句
SELECT column_name, COUNT(column_name) as count FROM table_name GROUP BY column_name HAVING count > 1;
这个查询语句会返回重复的值以及它们出现的次数,然后可以根据需要删除这些重复的数据。
3、使用临时表或子查询
创建一个临时表或子查询来存储不重复的数据,然后从原始表中删除重复的数据。
这种方法通常适用于大型数据库,因为它可以有效地处理大量数据。
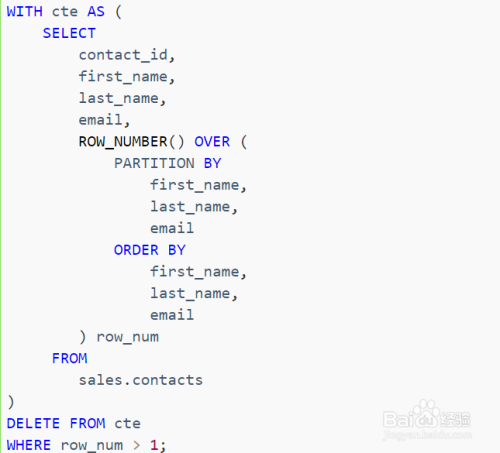
4、使用ROW_NUMBER()窗口函数
WITH cte AS (SELECT column_name, ROW_NUMBER() OVER (PARTITION BY column_name ORDER BY column_name) AS row_num FROM table_name) DELETE FROM cte WHERE row_num > 1;
这个查询语句使用窗口函数ROW_NUMBER()为每个重复的行分配一个唯一的行号,然后删除行号大于1的行,从而删除重复的数据。
5、使用JOIN操作删除重复数据
DELETE t1 FROM table_name t1 INNER JOIN (SELECT column_name, MIN(column_name) as min_value FROM table_name GROUP BY column_name HAVING COUNT(column_name) > 1) t2 ON t1.column_name = t2.min_value;
这个查询语句首先找到每个重复值的最小值,然后将原始表中与最小值相等的行删除,从而删除重复的数据。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/512495.html
 微信扫一扫
微信扫一扫