

通过将数据切分成多个块,分散存储在多台服务器上,实现数据的分布式存储和处理。
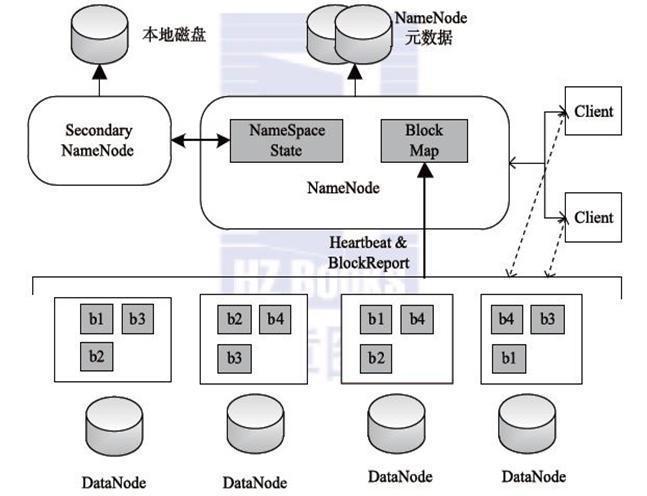
Hadoop分布式存储是通过Hadoop Distributed File System(HDFS)实现的,HDFS是一个高度容错性的系统,适合在廉价硬件上部署,它提供了高度的可靠性、可扩展性和容错性,可以支持大规模的数据集存储和处理。
以下是Hadoop分布式存储的实现步骤:

1、数据分块:
当用户向HDFS中写入数据时,数据会被分成多个块(block)。
每个块的大小默认为64MB,但可以根据需求进行调整。
块的大小是固定的,这样可以减少寻址开销,提高数据的读取效率。
2、数据副本:
HDFS会将每个数据块复制多份,以提供冗余备份。
默认情况下,每个数据块有三个副本。
副本的数量可以根据需求进行调整,增加副本可以提高数据的可靠性和容错性。
3、数据存储:
数据块的副本会被分布在不同的节点上。
每个节点都是一个独立的计算机,可以是普通的PC机或服务器。
节点之间通过心跳机制保持通信,以确保数据的一致性和可用性。
4、数据读取:
当用户需要读取数据时,HDFS会从最近的副本中读取数据块。
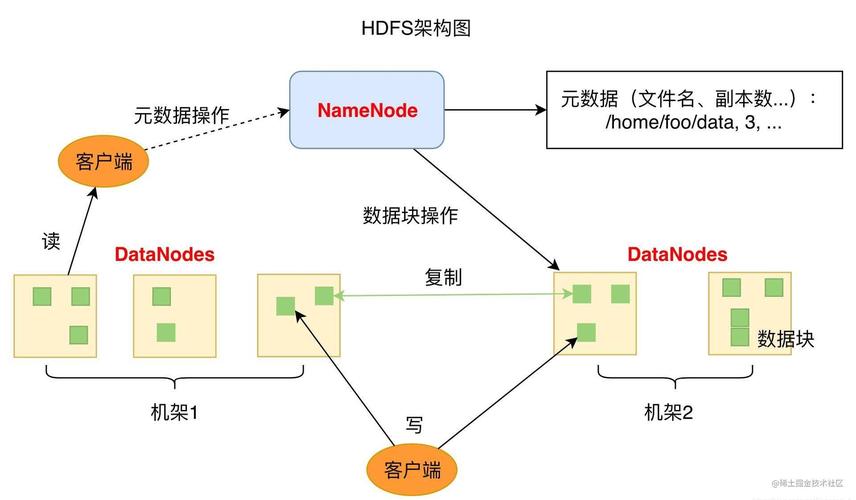
如果某个副本不可用,HDFS会自动从其他可用的副本中读取数据块。
这种机制保证了数据的高可用性和容错性。
5、数据迁移:
HDFS会定期检查数据块的副本数量,并根据需要进行迁移。
如果某个节点上的副本数量低于设定的阈值,HDFS会自动将该节点上的副本迁移到其他节点上。
这种机制可以保证数据的均衡分布和负载均衡。
6、故障恢复:
如果某个节点发生故障,HDFS会自动将该节点上的数据块副本迁移到其他节点上。
如果某个数据块的所有副本都丢失,HDFS会从其他节点上复制该数据块的副本。
这种机制保证了数据的可靠性和容错性。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/513778.html
 微信扫一扫
微信扫一扫