


CDH(Cloudera Distribution Including Apache Hadoop)是一个开源的大数据平台,提供了一套完整的解决方案来处理和管理大规模数据集,在CDH中,ETL(Extract, Transform, Load)是一个重要的组件,用于从不同的数据源提取数据,对数据进行转换和清洗,然后将数据加载到目标数据库或数据仓库中。
CDH ETL Job的基本概念
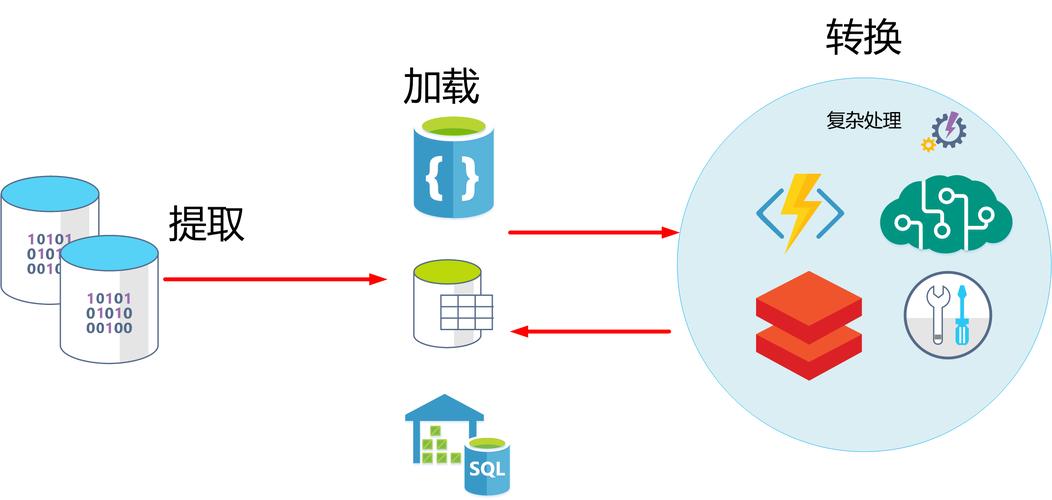
1. Extract(提取)
提取阶段是从不同的数据源中获取数据的过程,在CDH中,可以使用各种工具和技术来实现数据的提取,例如使用Sqoop工具从关系型数据库中提取数据,或者使用Flume从日志文件中提取数据。
2. Transform(转换)

转换阶段是对提取的数据进行处理和清洗的过程,在CDH中,可以使用各种数据处理工具和技术来实现数据的转换,例如使用MapReduce作业来进行数据的过滤、聚合和计算,或者使用Hive来进行数据的查询和分析。
3. Load(加载)
加载阶段是将转换后的数据加载到目标数据库或数据仓库中的过程,在CDH中,可以使用各种数据加载工具和技术来实现数据的加载,例如使用Sqoop将数据加载到关系型数据库中,或者使用Hadoop Distributed File System(HDFS)将数据加载到分布式文件系统中。
CDH ETL Job的工作流程
CDH ETL Job的工作流程可以分为以下几个步骤:
1、配置数据源:首先需要配置要提取的数据源,包括数据库连接信息、文件路径等。
2、编写ETL脚本:根据需求编写ETL脚本,包括提取数据的SQL语句、转换数据的MapReduce作业、加载数据的Sqoop命令等。
3、执行ETL作业:使用CDH提供的ETL工具执行ETL作业,将数据从源系统提取出来,经过转换和清洗后加载到目标系统中。
4、监控和调度:可以对ETL作业进行监控和调度,确保作业按时执行并输出结果。
5、错误处理和优化:如果ETL作业出现错误或性能问题,需要进行错误处理和优化,以提高作业的可靠性和效率。
CDH ETL Job的常用工具和技术
CDH提供了多种常用的ETL工具和技术,包括:
1、Sqoop:用于从关系型数据库中提取数据的工具,支持多种关系型数据库,如MySQL、Oracle等。
2、Flume:用于从日志文件中提取数据的工具,支持多种日志格式,如JSON、XML等。
3、MapReduce:用于对数据进行转换和清洗的分布式计算框架,可以进行数据的过滤、聚合和计算等操作。
4、Hive:用于进行数据查询和分析的分布式数据仓库,支持SQL语言和自定义函数。
5、Sqoop:用于将数据加载到关系型数据库中的工具,支持多种关系型数据库,如MySQL、Oracle等。
6、HDFS:用于将数据加载到分布式文件系统中的工具,支持多种文件格式,如文本、二进制等。
CDH ETL Job的应用场景
CDH ETL Job适用于以下应用场景:
1、数据采集和清洗:从多个数据源中采集数据,并对数据进行清洗和转换,以满足后续分析和建模的需求。
2、数据集成和迁移:将多个数据源中的数据集成到一个统一的数据仓库中,并进行数据的迁移和同步。
3、数据分析和挖掘:对大量的数据进行分析和挖掘,以发现隐藏的模式和关联性。
4、报表生成和可视化:根据业务需求生成各种报表和可视化图表,以帮助决策者做出准确的决策。
CDH ETL Job的优势和挑战
CDH ETL Job具有以下优势:
1、可扩展性:CDH ETL Job可以处理大规模的数据集,并支持分布式计算和存储。
2、灵活性:CDH ETL Job可以根据需求灵活地选择和使用各种ETL工具和技术。
3、高性能:CDH ETL Job可以利用分布式计算和存储的优势,实现高效的数据处理和加载。
CDH ETL Job也面临一些挑战:
1、复杂性:CDH ETL Job涉及多个环节和工具,需要具备一定的技术能力和经验。
2、维护性:CDH ETL Job需要定期进行维护和优化,以确保作业的稳定性和性能。
3、安全性:CDH ETL Job需要保护数据的安全性和隐私性,防止数据泄露和滥用。
CDH ETL Job的发展趋势和展望
随着大数据技术的不断发展和应用,CDH ETL Job也将面临一些新的发展趋势和挑战:
1、自动化:随着人工智能和机器学习技术的发展,CDH ETL Job将越来越倾向于自动化和智能化。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/522568.html
 微信扫一扫
微信扫一扫 