



CDH(Cloudera Distribution Including Apache Hadoop)是一个开源的大数据平台,它提供了一套完整的解决方案,用于构建、部署和管理企业级的大数据环境,CDH基于Apache Hadoop和相关的生态系统组件,包括Hive、HBase、Impala、Spark等,为用户提供了丰富的数据处理和分析功能。
1. CDH的特点
CDH具有以下几个特点:
可扩展性:CDH支持大规模的数据处理和存储,可以随着业务需求的增长进行水平扩展。
高可用性:CDH提供了高可用性的架构设计,确保数据的安全性和可靠性。
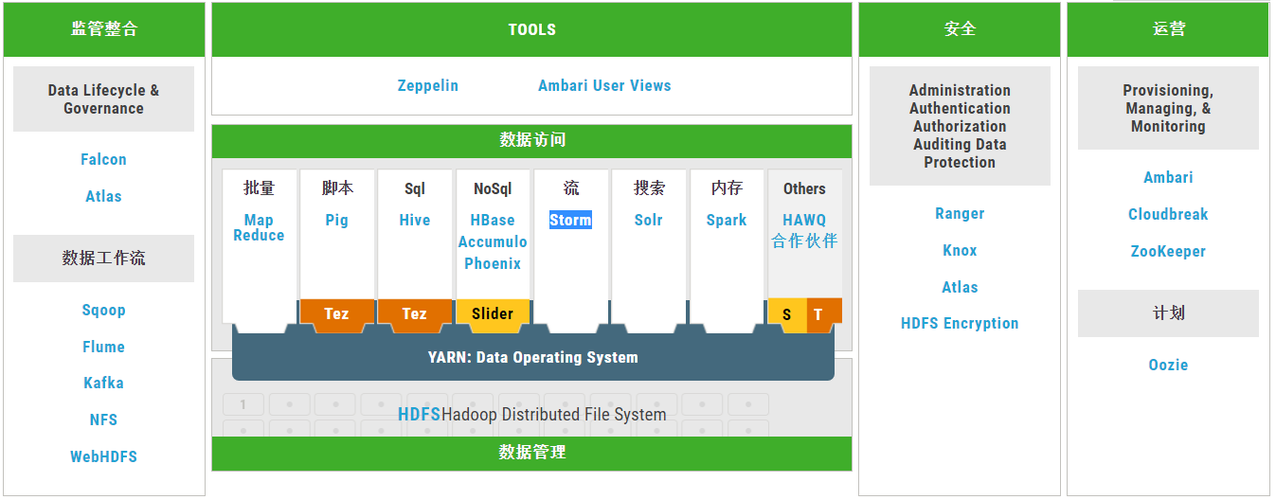
集成性:CDH集成了多个大数据处理工具和技术,方便用户进行数据处理和分析。
易用性:CDH提供了友好的用户界面和简化的管理工具,使用户可以快速上手并使用大数据平台。
2. CDH支持的大数据平台简介
CDH支持的大数据平台主要包括以下几个方面:
2.1 Apache Hadoop
Apache Hadoop是CDH的核心组件之一,它是一个开源的分布式计算框架,用于处理大规模数据集,Hadoop主要由两个核心组件组成:HDFS(Hadoop Distributed File System)和MapReduce。
HDFS:HDFS是一个分布式文件系统,用于存储和管理大规模数据集,它将数据切分成块,并将这些块分布在多个节点上进行存储,以提高数据的可靠性和容错能力。
MapReduce:MapReduce是一个并行计算模型,用于在分布式环境中执行大规模数据处理任务,它将任务分解为多个子任务,并在多个节点上并行执行这些子任务,以提高计算效率。
2.2 Apache Hive
Apache Hive是一个基于SQL的数据仓库查询工具,它允许用户使用类似于SQL的语法来查询和分析存储在Hadoop集群中的数据,Hive将SQL语句转换为MapReduce任务,并在Hadoop集群上执行这些任务。
2.3 Apache HBase
Apache HBase是一个分布式列式数据库,用于存储和管理大规模结构化数据,HBase与HDFS紧密集成,可以在Hadoop集群上提供高性能的数据读写服务。
2.4 Apache Impala
Apache Impala是一个基于内存的实时数据分析引擎,它提供了低延迟的查询性能和高并发的处理能力,Impala可以直接访问存储在HDFS、HBase和其他数据源中的数据,而无需转换为MapReduce任务。
2.5 Apache Spark
Apache Spark是一个通用的大数据处理引擎,它提供了丰富的数据处理和分析功能,Spark支持多种数据处理模式,包括批处理、流处理和交互式分析,Spark与Hadoop生态系统中的其他组件(如HDFS、Hive、HBase等)紧密集成,可以提供高性能的数据处理和分析能力。
3. CDH的应用场景
CDH适用于以下几种应用场景:
数据仓库:CDH提供了强大的数据仓库功能,可以将结构化和非结构化的数据集中存储和管理起来,并通过Hive等工具进行查询和分析。
实时数据分析:CDH集成了Impala等实时数据分析引擎,可以对大规模数据进行低延迟的查询和分析。
机器学习:CDH提供了丰富的机器学习库和工具,可以用于构建和训练各种机器学习模型。
日志分析:CDH可以处理大量的日志数据,并提供强大的日志分析功能,帮助用户发现和解决潜在的问题。
4. 相关的问题与解答
问题1:CDH与开源大数据平台的关系是什么?
答:CDH是基于开源大数据平台Apache Hadoop的一个发行版,它提供了一套完整的解决方案,用于构建、部署和管理企业级的大数据环境,CDH集成了多个大数据处理工具和技术,方便用户进行数据处理和分析。
问题2:CDH支持哪些大数据处理工具和技术?
答:CDH支持多个大数据处理工具和技术,包括Apache Hadoop、Apache Hive、Apache HBase、Apache Impala、Apache Spark等,这些工具和技术可以用于存储、管理和处理大规模数据集,并提供丰富的数据处理和分析功能。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/522629.html
 微信扫一扫
微信扫一扫