

遍历map_infomap算法(Infomap)是一种用于网络结构学习的算法,它可以从无向图数据中自动推断出社区结构,下面是关于遍历map_infomap算法的详细步骤:
算法概述
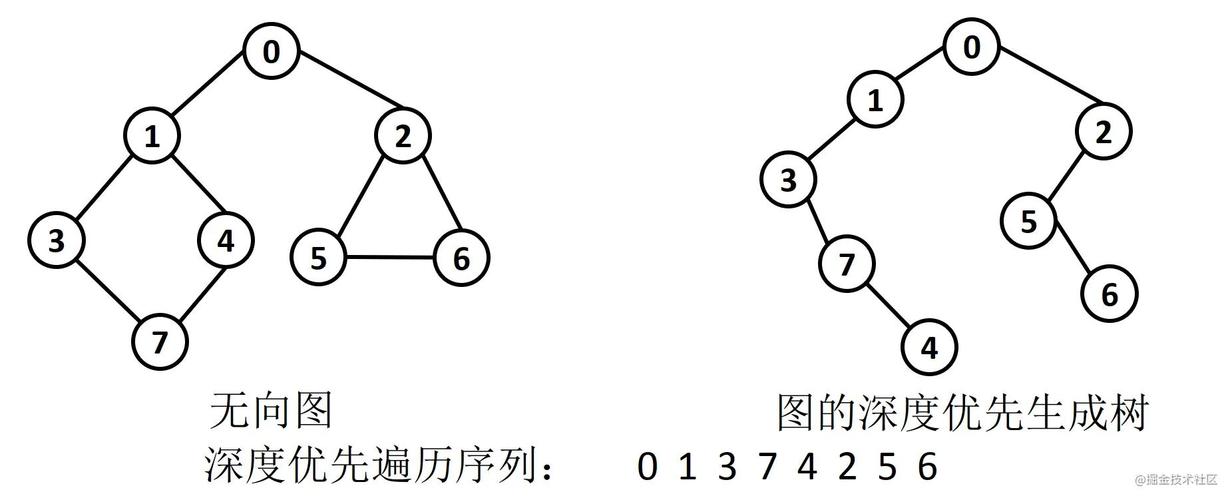
1、算法输入:无向图数据和相应的节点标签信息。

2、算法输出:社区划分结果。
算法步骤
1、初始化:将每个节点视为一个独立的社区,并计算每个节点的局部相似度。
2、合并社区:根据局部相似度,将相似度高的节点进行合并,形成更大的社区。
3、更新相似度:重新计算被合并节点及其邻居节点的相似度,以及整个图中其他节点的相似度。
4、判断收敛性:如果相似度不再发生显著变化,则算法收敛,否则返回步骤2继续合并社区。
5、输出结果:将图中的节点按照所属社区进行标记。
算法参数
1、α(alpha):控制相似度阈值的参数,取值范围为0到1之间,较小的α值会导致更多的社区划分,较大的α值会导致更少的社区划分。
2、β(beta):控制合并社区时相似度阈值的参数,取值范围为0到1之间,较小的β值会导致更多的合并操作,较大的β值会导致较少的合并操作。
算法实现示例
以下是使用Python语言实现遍历map_infomap算法的代码示例:
import infomap as im
加载无向图数据和节点标签信息
graph = im.Graph(directed=False) # 创建无向图对象
graph.load("data.txt") # 加载图数据文件
labels = graph.get_node_attributes() # 获取节点标签信息
设置算法参数
alpha = 0.8 # 相似度阈值参数α
beta = 0.5 # 合并社区时相似度阈值参数β
运行算法进行社区划分
community_partition = im.CommunityDetection().run_multilevel(graph, alpha, beta)
输出社区划分结果
for node in community_partition:
print(f"Node {node} belongs to community {community_partition[node]}")
相关问题与解答
问题1:遍历map_infomap算法适用于哪些类型的网络数据?
答:遍历map_infomap算法适用于无向图数据,即边没有方向性的网络数据,它能够自动从无向图数据中学习出社区结构,无需事先了解网络的结构或属性信息。
问题2:遍历map_infomap算法中的参数α和β的作用是什么?如何选择合适的参数值?
答:参数α是控制相似度阈值的参数,决定了将两个节点视为同一社区所需的相似度程度;参数β是控制合并社区时相似度阈值的参数,决定了在合并社区时需要达到的相似度程度,合适的参数值取决于具体的网络数据和应用场景,通常可以通过多次试验和比较不同参数值的效果来确定最佳参数组合。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/523508.html
 微信扫一扫
微信扫一扫