

MapReduce是一种并行处理引擎,它将大规模数据集分解为多个小任务,并在多台计算机上同时执行这些任务。
并行处理引擎MapReduce是一种用于大规模数据处理的编程模型,它由Google公司提出,并成为了大数据处理领域的重要工具之一,MapReduce将数据分成多个小任务,并在多个计算节点上并行执行这些任务,最后将结果合并起来得到最终结果。
MapReduce的基本概念和原理
1、Mapper(映射器):负责将输入数据拆分成多个键值对,并对每个键值对进行处理。
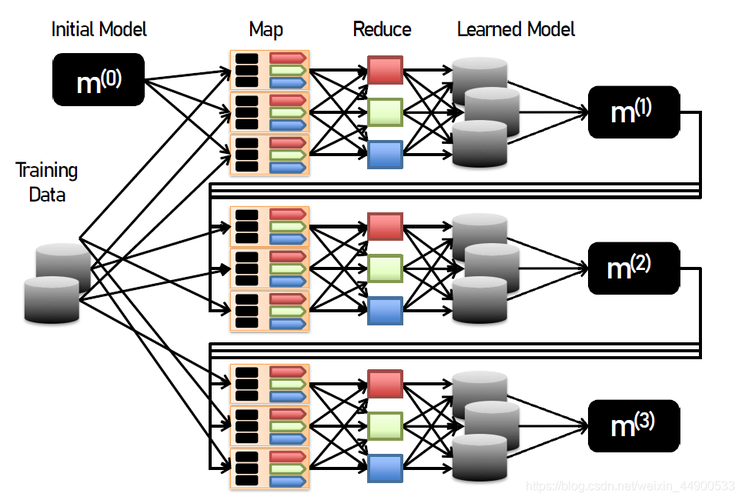

2、Reducer(归约器):负责将Mapper输出的相同键的值进行合并和处理,最终生成结果。
3、分区:将输入数据划分成多个部分,每个部分交给一个Mapper进行处理。
4、排序和合并:Mapper输出的键值对按照键进行排序,然后交给对应的Reducer进行处理。
5、并行化:通过将数据分割成多个分区和同时运行多个Mapper和Reducer来实现并行处理。
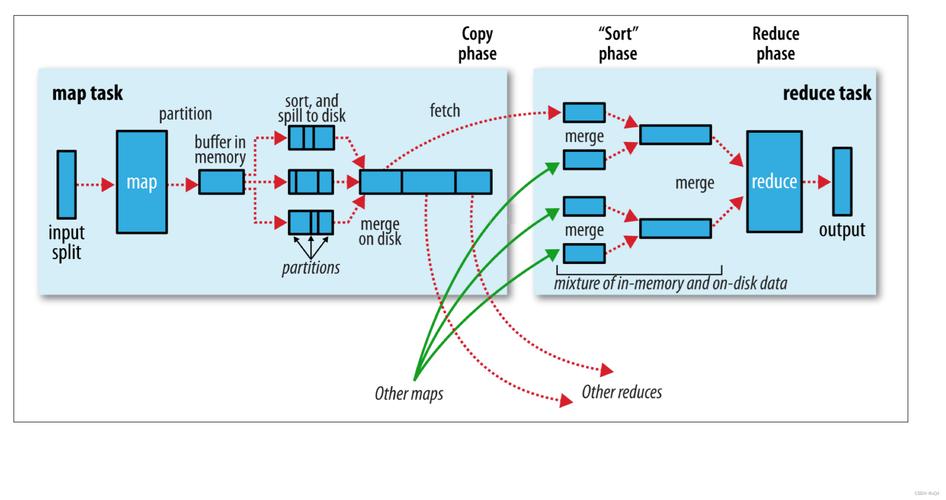
MapReduce的工作流程
1、输入分割:将输入数据分割成多个分区,每个分区交给一个Mapper进行处理。
2、Map阶段:Mapper读取输入数据,并根据指定的映射函数将数据转换成键值对。
3、Shuffle阶段:将Mapper输出的键值对按照键进行排序,并将相同键的值分配给同一个Reducer。
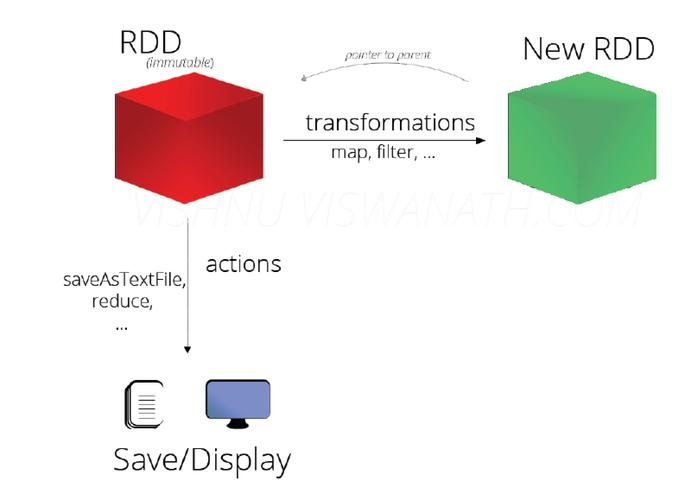
4、Reduce阶段:Reducer接收到所有具有相同键的值后,根据指定的归约函数对这些值进行处理,并生成最终结果。
5、输出:将Reducer生成的结果输出。
MapReduce的优势和应用
1、可扩展性:可以通过增加计算节点来提高处理能力。
2、容错性:如果某个节点出现故障,可以重新调度任务到其他节点上执行。
3、简单易用:提供了简单的接口和编程模型,使得开发人员可以专注于数据处理逻辑而无需关注分布式计算的细节。
4、广泛应用:被广泛应用于大数据分析、日志处理、机器学习等领域。
相关问题与解答:
1、MapReduce适用于哪些类型的数据处理?
答:MapReduce适用于大规模数据的批量处理,特别是对于需要对大量数据进行过滤、聚合和排序等操作的场景非常适用。
2、MapReduce如何处理实时数据流?
答:MapReduce更适合处理离线批处理任务,对于实时数据流的处理可以使用其他的流式处理框架,如Apache Storm或Apache Flink等。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/525247.html
 微信扫一扫
微信扫一扫