

Structured Streaming 任务提交方式变更,可以通过设置
spark.sql.streaming.checkpointLocation参数来实现。
Structured Streaming 是 Apache Spark 的一个扩展,它允许用户以实时流的方式处理数据,与传统的批处理任务不同,Structured Streaming 可以连续不断地接收数据,并立即进行处理,这种实时处理能力使得 Structured Streaming 在许多场景中具有优势,如实时数据分析、监控和警报等。
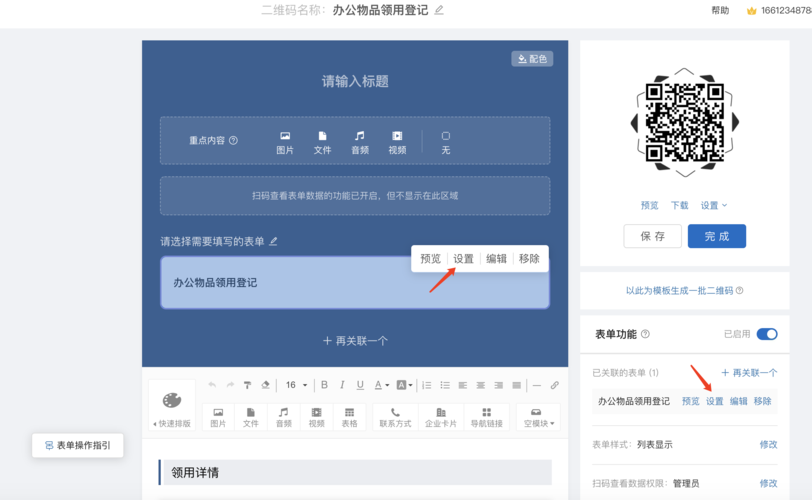
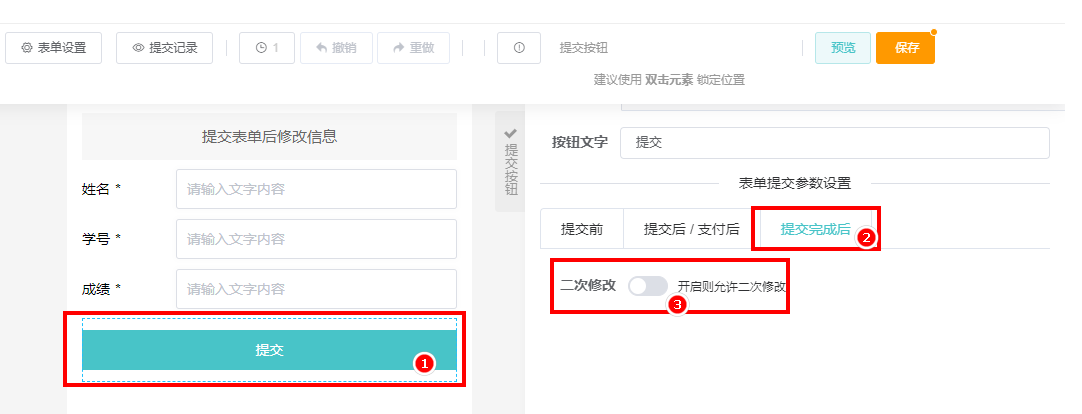
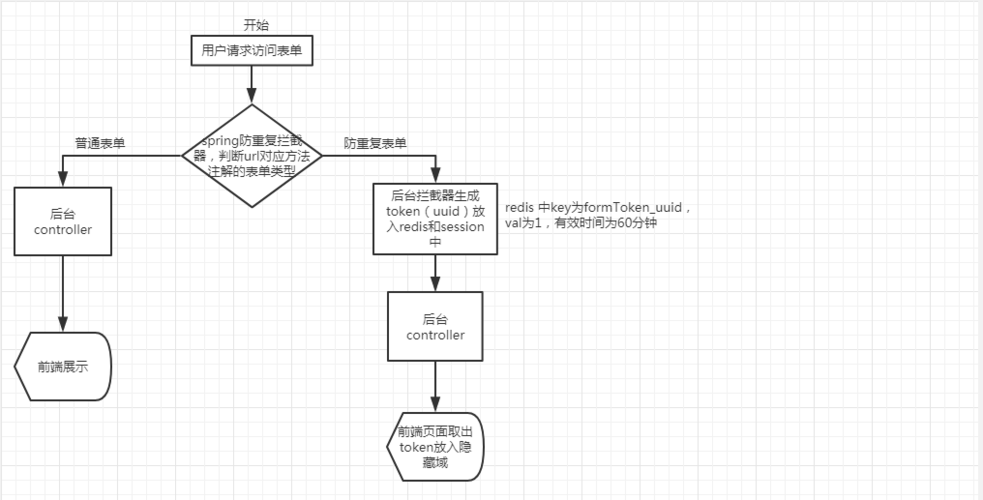
表单的提交方式
Structured Streaming 任务提交方式主要有以下几种:

1、local[*]:在单个机器上运行,使用所有可用的核心进行计算,这是最简单的提交方式,适用于测试和调试。
2、local[N]:在单个机器上运行,使用 N 个核心进行计算,可以通过设置环境变量或命令行参数来指定 N 的值。
3、yarnclient:在 YARN(Yet Another Resource Negotiator)集群上运行,客户端负责与集群通信和管理资源,这是最常用的提交方式,适用于生产环境。
4、yarncluster:在 YARN 集群上运行,任务与驱动程序一起提交到集群,共享资源,这种方式适用于需要大量内存的任务。
5、kafka:从 Kafka 主题中读取数据,并将结果写入另一个 Kafka 主题,这种方式适用于实时数据流处理。
变更提交方式的方法
要更改 Structured Streaming 任务的提交方式,可以在创建 StreamingContext 时通过设置相应的参数来实现,以下是一个简单的示例:
from pyspark.sql import SparkSession
from pyspark.sql.functions import *
from pyspark.sql.types import *
创建 SparkSession
spark = SparkSession
.builder
.appName("StructuredStreamingExample")
.getOrCreate()
定义输入源和输出目标
input_data = spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "localhost:9092")
.option("subscribe", "test_topic")
.load()
对数据进行处理
processed_data = input_data
.selectExpr("CAST(key AS STRING)", "CAST(value AS BINARY)")
.groupByKey()
.count()
设置输出目标和提交方式
query = processed_data
.writeStream
.outputMode("complete")
.format("console")
.option("truncate", "false")
.trigger(processingTime="1 minute")
.start("localhost:9092")
更改提交方式为 yarncluster
query = query._jvm.getConf().setAppName("StructuredStreamingExample").setMaster("yarncluster")
归纳
Structured Streaming 提供了多种提交方式,可以根据实际需求选择合适的方式,在创建 StreamingContext 时,可以通过设置相应的参数来更改提交方式,这些参数包括应用程序名称、资源管理器类型、核心数量等,了解这些参数的作用和如何设置它们,可以帮助我们更好地管理和优化 Structured Streaming 任务。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/527367.html
 微信扫一扫
微信扫一扫