

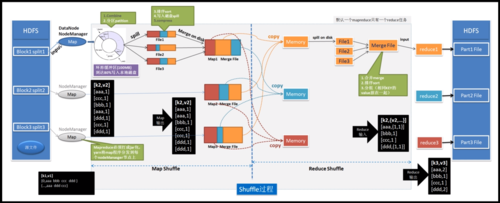
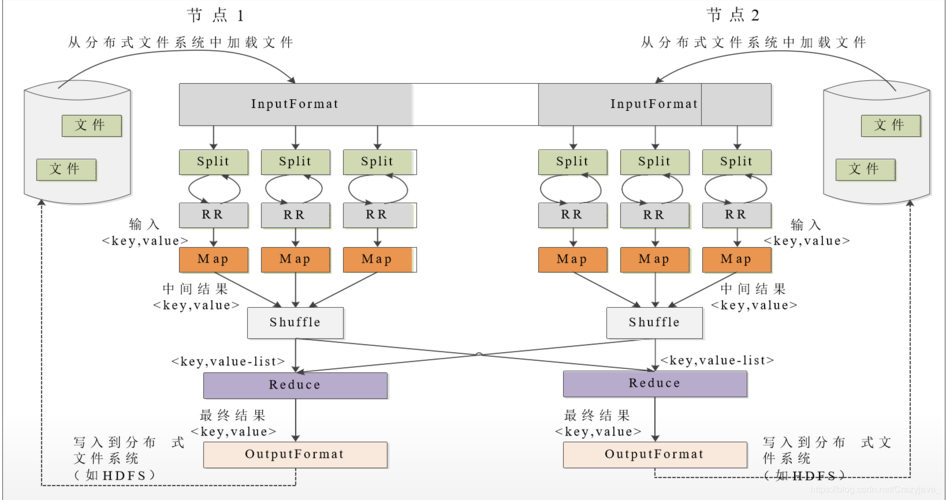
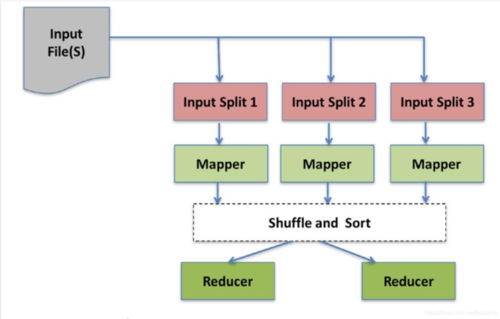
MapReduce是一种并行数据处理框架,它的核心思想是将大规模数据集分解成多个小任务,然后通过多台计算机并行处理这些任务,最后将结果合并得到最终结果,MapReduce与其他组件的关系如下:
1、Hadoop

Hadoop是一个开源的分布式计算框架,它提供了一个可靠、高可用、可扩展的数据存储和处理平台,Hadoop的核心组件包括HDFS(Hadoop Distributed File System)和MapReduce,HDFS负责存储数据,而MapReduce负责处理数据,MapReduce是Hadoop生态系统中的一个重要组成部分。
2、YARN(Yet Another Resource Negotiator)
YARN是Hadoop的一个资源管理系统,它负责管理集群中的计算资源和调度任务,在YARN中,MapReduce作为一种应用模型,可以通过YARN进行任务的提交、调度和监控,MapReduce与YARN密切相关。
3、Hive
Hive是一个基于Hadoop的数据仓库工具,它提供了一种类SQL的查询语言(HiveQL),可以将复杂的数据分析任务转化为简单的SQL语句,Hive底层使用MapReduce作为执行引擎,MapReduce与Hive之间存在紧密的联系。
4、Pig
Pig是一个基于Hadoop的大数据分析平台,它提供了一种高级的数据流语言(Pig Latin),可以简化MapReduce编程,Pig将用户编写的脚本转换为MapReduce任务,然后通过Hadoop执行,MapReduce与Pig之间存在密切的关系。
5、Spark
Spark是一个基于内存的分布式计算框架,它提供了比MapReduce更高效的数据处理能力,尽管Spark与MapReduce在设计理念上有所不同,但它们都是用于处理大规模数据的并行计算框架,在某些场景下,Spark可以替代MapReduce进行数据处理,MapReduce与Spark之间存在一定的竞争关系。
6、Flink
Flink是一个基于流式计算和批处理的统一数据处理框架,它可以处理实时数据和离线数据,Flink底层也使用了类似MapReduce的并行计算模型,MapReduce与Flink之间存在一定的联系。
MapReduce是Hadoop生态系统中的一个重要组件,它与其他组件如YARN、Hive、Pig、Spark和Flink之间存在密切的关系,这些组件共同构成了一个完整的大数据处理生态链,为用户提供了丰富的数据处理功能。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/527482.html
 微信扫一扫
微信扫一扫