

表格文字识别是一种将纸质或电子表格中的文字信息转换为可编辑文本的技术,广泛应用于数据处理、文档管理等领域。
【表格文字识别_附录】
小标题1:表格文字识别的基本原理
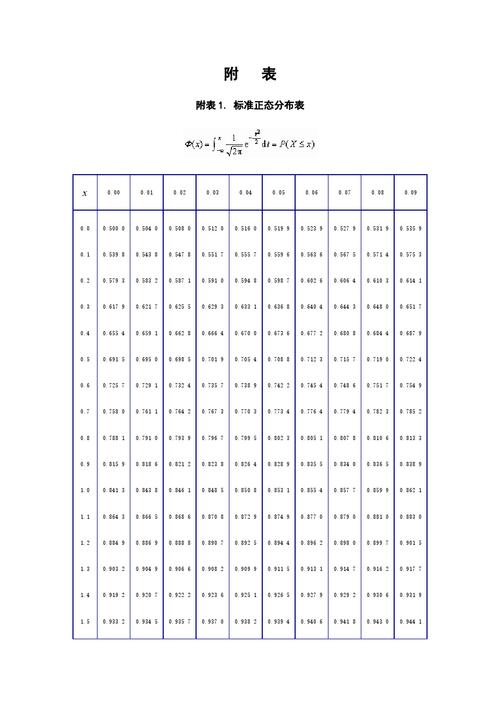

单元表格1:表格文字识别的步骤
| 步骤 | 描述 |
| 图像预处理 | 对输入的图像进行去噪、二值化等处理,以便后续的文字识别。 |
| 文本区域检测 | 通过边缘检测、连通域分析等方法,将图像中的文本区域定位出来。 |
| 字符分割 | 将文本区域中的字符进行分割,以便后续的字符识别。 |
| 字符识别 | 对分割后的字符进行识别,常用的方法有基于模板匹配和基于机器学习的方法。 |
| 结果输出 | 将识别出的字符按照一定的格式输出,如文本或电子表格。 |
小标题2:常见的表格文字识别工具
单元表格2:常见的表格文字识别工具及其特点
| 工具名称 | 特点 |
| Tesseract OCR | 开源的OCR引擎,支持多种语言,具有较高的准确性和灵活性。 |
| ABBYY FineReader | 商业OCR软件,具有较好的准确性和易用性,支持多种文件格式。 |
| Microsoft Office Lens | 微软推出的移动应用,可以方便地将纸质文档转换为电子表格。 |
| Google Cloud Vision API | 谷歌提供的云端OCR服务,支持多种语言和文件格式,具有较高的准确性。 |
小标题3:表格文字识别的应用场景
单元表格3:表格文字识别的应用场景示例
| 应用场景 | 描述 |
| 纸质文档数字化 | 将纸质文档中的数据转换为电子表格,方便存储和分析。 |
| 数据录入自动化 | 通过识别纸质表格中的数据,自动将其录入到电子系统中。 |
| 报表生成与分析 | 通过识别财务报表中的表格数据,自动生成报表并进行数据分析。 |
| 发票报销管理 | 通过识别发票中的表格信息,实现报销流程的自动化和规范化。 |
相关问题与解答:
问题1:如何提高表格文字识别的准确性?
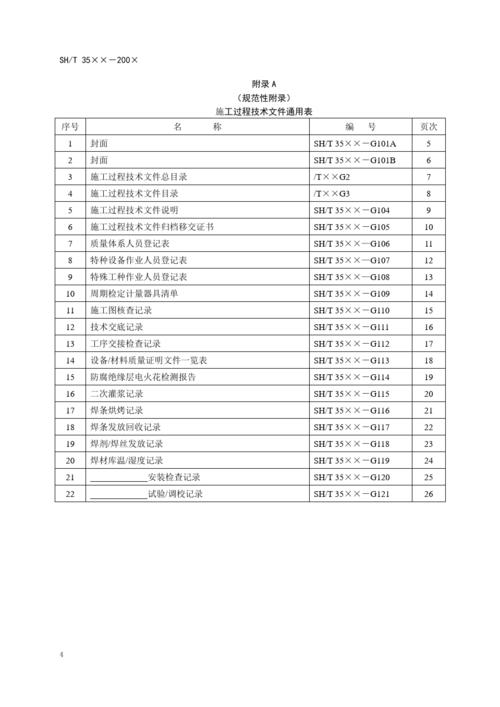
答:可以通过以下方法提高表格文字识别的准确性:1)优化图像预处理,减少噪声和干扰;2)选择合适的文本区域检测算法,确保准确地定位文本区域;3)使用更准确的字符识别算法,如基于深度学习的方法;4)对于特定的应用场景,可以对识别结果进行后处理,如去除错误字符或纠正错误的行列关系。
问题2:如何处理表格中的特殊格式和样式?
答:处理表格中的特殊格式和样式可以考虑以下方法:1)在图像预处理阶段,对特殊格式和样式进行针对性的处理,如去除阴影、调整亮度等;2)在字符分割阶段,根据特殊格式和样式的特点,设计相应的分割规则;3)在字符识别阶段,针对特殊格式和样式的字符,使用专门的识别模型或规则进行处理;4)对于特定的应用场景,可以对识别结果进行后处理,如保留特殊格式和样式的信息。

原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/535574.html
 微信扫一扫
微信扫一扫