

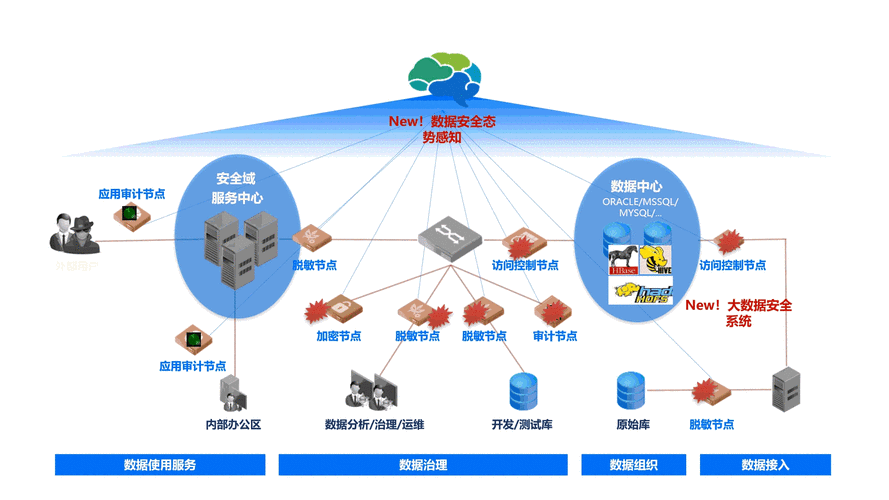

本地软件数据存到云服务器数据库的典型场景是从本地采集动态日志保存到HDFS,下面将详细介绍该过程的步骤和相关配置。
1、安装和配置Hadoop集群:
在云服务器上安装Hadoop集群,包括HDFS、YARN等组件。
配置Hadoop集群的相关参数,如HDFS的副本数、存储路径等。
2、创建日志采集程序:
开发一个本地应用程序,用于采集动态日志数据。
该程序需要能够将采集到的日志数据按照一定的格式进行组织和处理。
3、配置日志采集程序:
在本地应用程序中添加Hadoop客户端依赖,以便与HDFS进行交互。
配置日志采集程序的相关参数,如日志文件的路径、HDFS的目标路径等。
4、启动日志采集程序:
运行本地应用程序,开始采集动态日志数据。
程序将采集到的日志数据按照一定的格式进行处理,并写入本地文件。
5、将本地日志文件上传到HDFS:
使用Hadoop命令行工具或API,将本地的日志文件上传到HDFS的目标路径。
确保上传过程中数据的完整性和一致性。
6、监控和管理日志数据:
使用Hadoop的管理界面或命令行工具,监控和管理上传到HDFS的日志数据。
可以进行数据的查询、统计和分析等操作。
相关问题与解答:
问题1:如何确保上传到HDFS的日志数据的完整性和一致性?
答:可以通过以下方式确保上传到HDFS的日志数据的完整性和一致性:
使用Hadoop的数据冗余机制,如副本数设置,来保证数据的可靠性。
在上传过程中使用事务机制,确保每个日志文件都成功上传后再进行下一个文件的上传。
定期进行数据校验和修复,检查上传的数据是否完整且一致。
问题2:如何对上传到HDFS的日志数据进行查询和分析?
答:可以使用Hadoop提供的工具和API对上传到HDFS的日志数据进行查询和分析,具体步骤如下:
使用Hadoop的命令行工具,如Hive或MapReduce,编写查询语句或程序来分析数据。
使用Hadoop的管理界面,如Hue或Apache Ambari,创建可视化的查询和分析界面。
根据具体的需求,选择合适的查询和分析方法,如聚合、过滤、排序等操作。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/539815.html
 微信扫一扫
微信扫一扫