

CDH搭建三台服务器内存配置
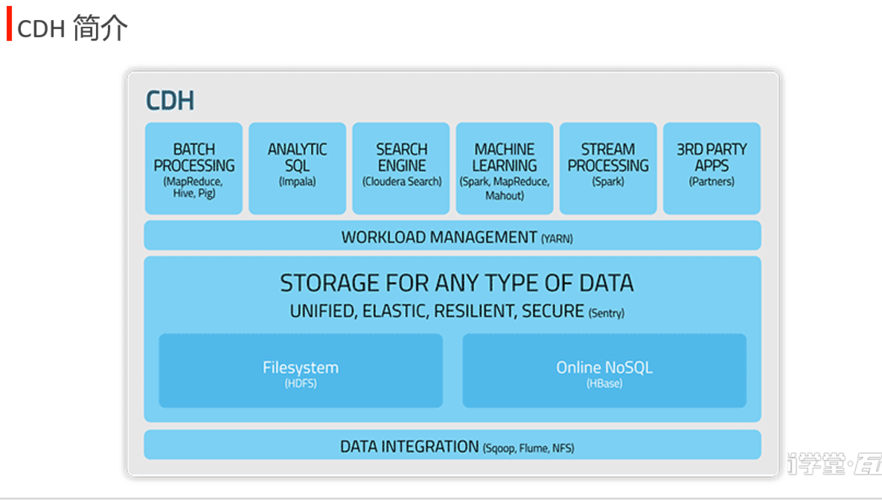

在搭建CDH(Cloudera Distribution Hadoop)集群时,需要合理配置服务器的内存,本文将详细介绍如何在三台服务器上进行CDH部署,并给出相应的内存配置建议。
硬件准备
我们需要准备三台服务器,每台服务器的配置如下:
CPU:至少4核
内存:根据实际需求和数据量来确定,一般建议每台服务器至少8GB内存
硬盘:至少500GB的存储空间
操作系统准备
在每台服务器上安装CentOS 7操作系统,并完成以下基本配置:
1、更新系统软件包:
sudo yum update y
2、关闭防火墙:
sudo systemctl stop firewalld sudo systemctl disable firewalld
3、配置SSH免密码登录:
sudo sed i 's/#PasswordAuthentication yes/PasswordAuthentication yes/g' /etc/ssh/sshd_config sudo systemctl restart sshd
4、配置时间同步:
sudo yum install ntpdate y sudo ntpdate pool.ntp.org
安装Java环境
在每台服务器上安装Java环境,推荐使用JDK 8,执行以下命令进行安装:
sudo yum install java1.8.0openjdkdevel y
安装完成后,验证Java是否安装成功:
java version
输出结果应显示Java版本信息。
下载CDH安装包
从Cloudera官网下载CDH安装包,选择适合的版本进行下载,将下载好的安装包上传到每台服务器的/home目录下。
配置主机名和IP地址
在每台服务器上配置主机名和IP地址,执行以下命令:
sudo vi /etc/hosts
在文件中添加以下内容:
192、168.1.1 server1 192、168.1.2 server2 192、168.1.3 server3
保存并退出文件,然后执行以下命令修改主机名:
sudo vi /etc/hostname
将文件中的内容修改为对应的主机名,保存并退出文件,最后重启服务器使配置生效:
sudo reboot
配置SSH密钥对登录
在每台服务器上生成SSH密钥对,执行以下命令:
sshkeygen t rsa P '' f ~/.ssh/id_rsa
按照提示操作,设置密钥对的保存路径和密码,完成后,将公钥复制到其他两台服务器的~/.ssh/authorized_keys文件中,可以使用以下命令进行复制:
sshcopyid user@server2_ip_address # 将公钥复制到server2上 sshcopyid user@server3_ip_address # 将公钥复制到server3上
user是远程服务器上的用户名,server2_ip_address和server3_ip_address分别是server2和server3的IP地址,输入密码后,公钥将被复制到目标服务器上。
安装CDH组件和服务
在每台服务器上执行以下命令开始安装CDH组件和服务:
cd /home/cdhinstallationdirectory # 切换到安装目录的路径下,根据实际情况修改路径名和文件名 sudo sh cdhinstall.sh # 执行安装脚本开始安装过程,根据提示操作即可完成安装过程
安装过程中会询问一些配置选项,如数据库类型、Hadoop版本等,根据实际需求进行选择,安装完成后,可以通过访问Web界面来管理和监控CDH集群,默认情况下,Web界面的URL为http://server_ip_address:7180,其中server_ip_address是当前服务器的IP地址,使用浏览器访问该URL即可进入CDH管理界面。
通过以上步骤,我们可以在三台服务器上搭建起一个CDH集群,以下是两个与本文相关的问题及解答:
问题1:为什么需要合理配置服务器的内存?
答:合理配置服务器的内存可以提高CDH集群的性能和稳定性,如果内存过小,可能会导致MapReduce任务运行缓慢或失败;如果内存过大,则会造成资源浪费,根据实际需求和数据量来确定每台服务器的内存大小是很重要的,每台服务器至少需要8GB内存来满足大多数场景的需求,还可以根据具体业务需求进行进一步调整和优化。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/545571.html
 微信扫一扫
微信扫一扫