

【参数分类机器学习】
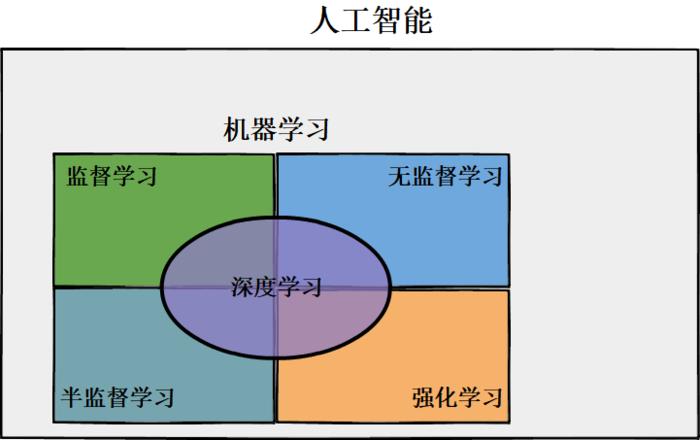

参数分类机器学习是一种基于模型的学习方法,通过训练一个模型来预测或分类输入数据,在这种方法中,我们首先定义一个模型,然后通过学习算法来调整模型的参数,使得模型能够更好地拟合训练数据,我们可以使用这个训练好的模型来对新的数据进行预测或分类。
参数分类机器学习可以分为以下几个步骤:
1、数据准备:我们需要收集和整理用于训练和测试的数据,这些数据可以是结构化的,如表格数据,也可以是非结构化的,如文本、图像或音频数据,数据准备阶段还包括数据清洗、特征选择和特征工程等任务。
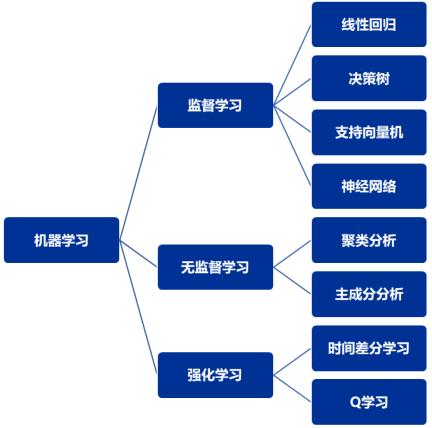
2、模型选择:根据问题的性质和数据的特点,我们需要选择一个合适的模型,常见的模型包括线性回归、逻辑回归、决策树、支持向量机、神经网络等。
3、模型训练:在选择了合适的模型之后,我们需要使用训练数据来训练这个模型,训练过程通常包括损失函数的定义、优化算法的选择和模型参数的更新等步骤。
4、模型评估:在模型训练完成之后,我们需要使用测试数据来评估模型的性能,常见的评估指标包括准确率、召回率、F1分数等。
5、模型应用:我们可以使用训练好的模型来对新的数据进行预测或分类。
【机器学习端到端场景】
端到端(EndtoEnd)学习是一种直接从原始输入数据到最终输出结果的学习方式,不需要手动设计中间的特征表示,在机器学习领域,端到端学习主要应用于以下几个方面:
1、语音识别:传统的语音识别系统通常需要先对语音信号进行预处理,提取出特征表示,然后再使用分类器进行识别,而端到端学习可以直接从原始语音信号到文本序列,避免了特征提取和分类器的复杂性。
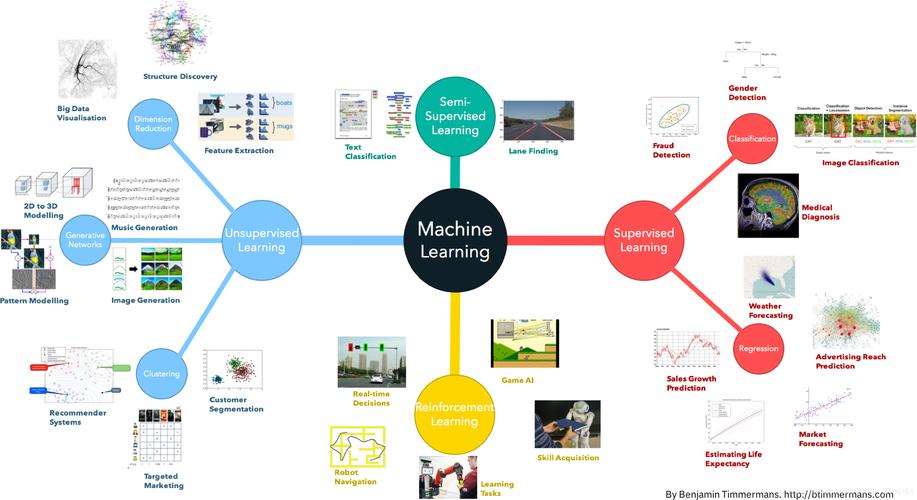
2、机器翻译:传统的机器翻译系统通常需要先对源语言进行分词和词性标注,然后构建词汇表和语法规则,再使用统计机器翻译方法进行翻译,而端到端学习可以直接从源语言句子到目标语言句子,避免了复杂的特征工程和中间表示。
3、图像识别:传统的图像识别系统通常需要先对图像进行预处理,提取出特征表示,然后再使用分类器进行识别,而端到端学习可以直接从原始图像到类别标签,避免了特征提取和分类器的复杂性。
4、文本生成:端到端学习可以用于生成文本,如对话系统、摘要生成等任务,这些任务通常需要将输入文本映射到一个连续的向量空间,然后通过解码器生成输出文本。
【参数分类机器学习与端到端学习的关系】
参数分类机器学习和端到端学习都是机器学习的方法,但它们之间存在一定的区别:
1、特征表示:参数分类机器学习需要手动设计特征表示,而端到端学习可以直接从原始输入数据学习特征表示,这使得端到端学习在一些任务上具有更好的性能和泛化能力。
2、模型结构:参数分类机器学习通常需要设计复杂的模型结构,如深度神经网络、决策树等,而端到端学习可以通过简单的模型结构实现复杂的任务,如卷积神经网络(CNN)用于图像识别、循环神经网络(RNN)用于序列生成等。
3、训练难度:参数分类机器学习的训练过程通常需要大量的计算资源和时间,而端到端学习由于其简单性,通常更容易训练和部署。
【与本文相关的问题】
1、参数分类机器学习和端到端学习各有什么优缺点?
答:参数分类机器学习的优点是可以灵活地设计模型结构和特征表示,适用于各种任务;缺点是需要大量的计算资源和时间进行训练,且对特征工程的要求较高,端到端学习的优点是可以直接从原始输入数据学习特征表示,简化了模型设计和训练过程;缺点是在某些任务上可能无法达到与传统方法相媲美的性能。
2、如何选择合适的机器学习方法?
答:选择合适的机器学习方法需要考虑问题的性质、数据的特点以及可用的资源等因素,对于一些复杂的任务,可以尝试使用参数分类机器学习;而对于一些简单的任务,可以尝试使用端到端学习,还可以通过实验对比不同方法的性能,以确定最适合当前任务的方法。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/545761.html
 微信扫一扫
微信扫一扫