

端到端场景

传递学习(Transfer Learning)是机器学习中的一种策略,它允许我们使用在一个任务上预先训练好的模型作为另一个任务的起点,这种方法的主要优点是可以利用已有的知识来加速新任务的学习过程,或者在数据量较少的情况下提高模型的性能,在这篇文章中,我们将深入探讨传递学习在端到端(EndtoEnd)场景中的应用。
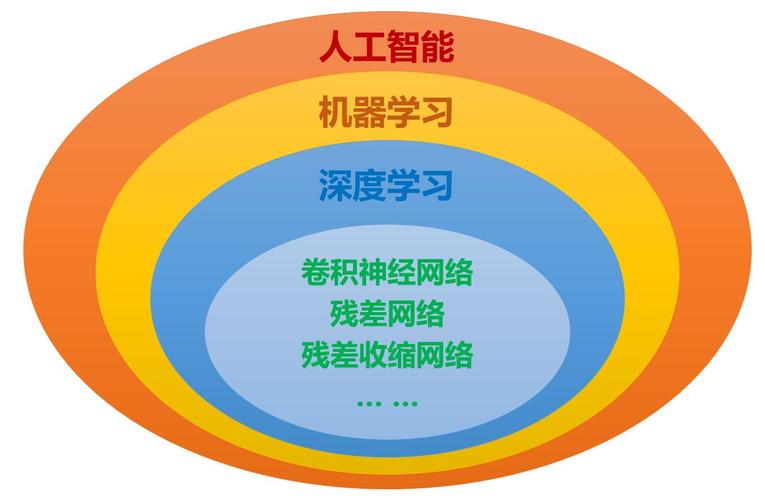
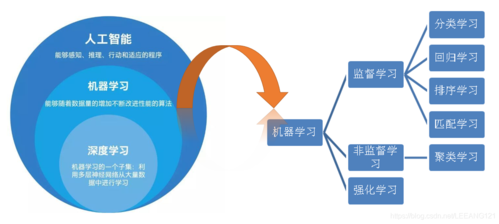
1. 传递学习的基本概念
传递学习的基本思想是将一个预训练的模型应用到新的任务上,而不是从头开始训练模型,预训练模型通常在一个大规模的数据集上进行训练,ImageNet,这个数据集包含了数百万张带有标签的图片,通过这种方式,预训练模型可以学习到大量的通用特征,这些特征对于许多不同的任务都是有用的。
2. 端到端学习的基本概念
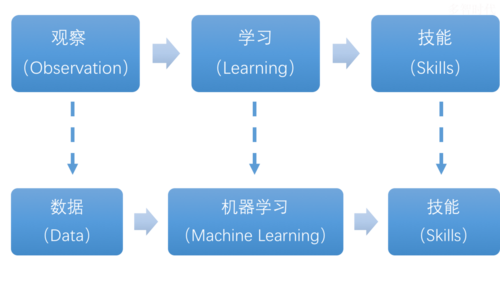
端到端学习是一种直接从输入数据到输出结果的训练方法,不需要手动设计中间的特征表示,在传统的机器学习任务中,我们通常会先手动设计一些特征,然后将这些特征输入到模型中进行训练,而在端到端学习中,模型可以直接从原始数据中学习到有用的特征和预测结果。
3. 传递学习在端到端场景中的应用
3.1 图像分类
在图像分类任务中,我们可以使用预训练的卷积神经网络(CNN)作为特征提取器,然后添加一个新的全连接层来进行分类,这样,我们就可以利用预训练模型学习到的通用特征,而不需要从头开始训练模型。
3.2 语音识别
在语音识别任务中,我们可以使用预训练的循环神经网络(RNN)或者长短期记忆网络(LSTM)来处理序列数据,我们可以添加一个新的全连接层来进行词级别的分类,这样,我们就可以利用预训练模型学习到的语音特征,而不需要从头开始训练模型。
3.3 机器翻译
在机器翻译任务中,我们可以使用预训练的编码器解码器结构来处理序列数据,编码器将源语言的句子编码成一个固定长度的向量,解码器将这个向量解码成目标语言的句子,这样,我们就可以利用预训练模型学习到的语言特征,而不需要从头开始训练模型。
4. 传递学习的挑战和解决方案
尽管传递学习有很多优点,但是它也有一些挑战,预训练模型可能并不完全适合新的任务,因此可能需要对模型进行一些调整,预训练模型可能会过拟合新的任务,因此可能需要使用一些正则化技术来防止过拟合,预训练模型可能需要大量的计算资源和时间来训练。
为了解决这些挑战,我们可以采取以下几种策略:
微调(Finetuning):我们可以对预训练模型的一部分进行微调,以使其更适合新的任务,这通常是通过冻结一部分层的参数,然后只对剩余的层进行训练来实现的。
迁移学习(Transfer Learning):我们可以使用预训练模型的一部分作为新模型的基础,然后在此基础上添加一些新的层来适应新的任务,这种方法可以帮助我们减少训练时间和计算资源的消耗。
正则化(Regularization):我们可以使用一些正则化技术,如 dropout 或 L1/L2 正则化,来防止预训练模型过拟合新的任务。
5. 结论
传递学习是一种强大的机器学习策略,它可以帮助我们利用已有的知识来加速新任务的学习过程,或者在数据量较少的情况下提高模型的性能,在端到端场景中,我们可以使用预训练的模型作为特征提取器,然后添加一些新的层来进行预测,尽管传递学习有一些挑战,但是通过采取一些策略,我们可以有效地解决这些问题。
与本文相关的问题及解答:
问题1:传递学习是否总是优于从头开始训练模型?
答:传递学习并不总是优于从头开始训练模型,在某些情况下,从头开始训练模型可能会比使用传递学习得到更好的性能,当预训练模型和新任务之间的差异非常大时,或者当可用的数据量非常大时,从头开始训练模型可能会得到更好的结果,从头开始训练模型也可以让我们更好地控制模型的设计和优化过程。
问题2:如何选择合适的预训练模型?
答:选择合适的预训练模型需要考虑多个因素,包括预训练模型的类型、大小、复杂度、以及预训练模型和新任务之间的相似性等,我们应该选择与新任务最相似的预训练模型,我们还需要考虑预训练模型的大小和复杂度,以确保我们有足够的计算资源来运行预训练模型。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/545851.html
 微信扫一扫
微信扫一扫