

聚类系数算法是一种基于大数据的聚类方法,通过计算数据点之间的相似性来确定它们是否属于同一类别。
大数据聚类算法中的聚类系数算法(Clustering Coefficient)是一种用于衡量数据点之间连接紧密程度的指标,它可以帮助确定数据点之间的相似性,并将相似的数据点聚集在一起形成簇。
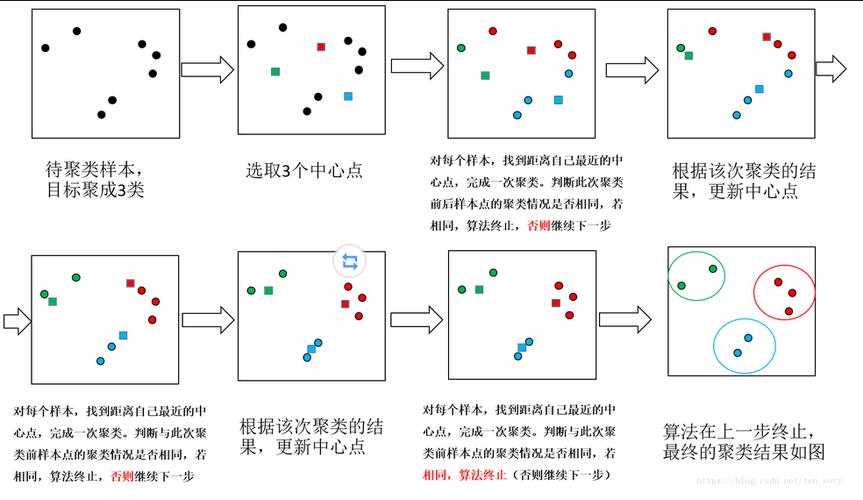

聚类系数算法的原理
聚类系数算法基于一个数据点与其邻居之间的连接情况来计算,对于一个数据点,其聚类系数表示与其相邻的数据点之间存在的边的数量占可能存在的边的最大数量的比例,具体步骤如下:
1、选择一个数据点作为起始点;
2、计算与该数据点直接相连的其他数据点的数量;
3、对于每个与起始点直接相连的数据点,计算它们之间可能存在的边的数量;
4、将所有可能的边的数量求和,得到可能存在的边的最大数量;
5、将实际存在的边的数量除以可能存在的边的最大数量,得到聚类系数。
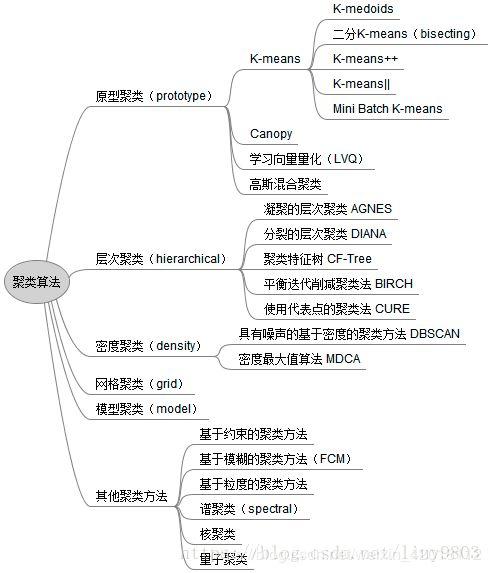
聚类系数算法的应用场景
聚类系数算法适用于各种类型的数据集,尤其适用于社交网络分析、图像分割、文本挖掘等领域,它可以帮助我们发现数据中的潜在模式和结构,从而进行更好的数据分析和决策。
相关参数设置
在使用聚类系数算法时,可以根据具体需求进行一些参数设置,如:
1、邻域大小:确定一个数据点的邻居数目,即与该数据点距离在一定范围内的数据点;
2、距离度量:选择一种合适的距离度量方法,如欧氏距离、曼哈顿距离等;
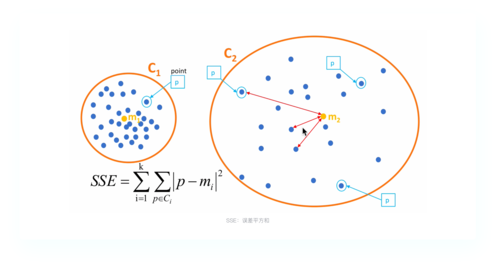
3、阈值:根据具体问题设定一个阈值,用于判断是否存在边。
相关问题与解答
问题1:聚类系数算法适用于哪些类型的数据集?
答:聚类系数算法适用于各种类型的数据集,尤其适用于社交网络分析、图像分割、文本挖掘等领域。
问题2:如何选择合适的邻域大小和距离度量方法?
答:选择合适的邻域大小和距离度量方法需要根据具体问题和数据集的特点来确定,可以尝试不同的参数组合,通过比较不同结果来选择最合适的参数。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/546435.html
 微信扫一扫
微信扫一扫