

大量数据处理
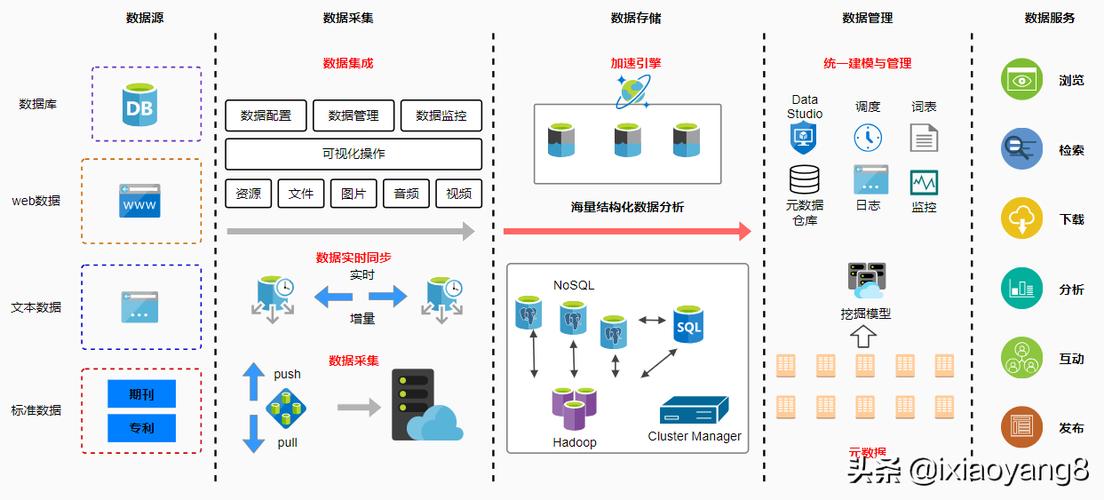

什么是大量数据处理?
大量数据处理是指对海量数据进行收集、存储、处理和分析的过程,随着互联网的发展,我们每天都会产生大量的数据,这些数据包括文本、图片、音频、视频等多种形式,对这些数据进行处理和分析,可以帮助我们更好地了解用户需求、优化产品和服务、提高决策效率等。
大量数据处理的方法
1、数据清洗:在数据处理过程中,需要对原始数据进行清洗,去除重复、错误和无关的数据,以提高数据质量。
2、数据转换:将原始数据转换为适合分析和处理的格式,如将文本数据转换为结构化数据,将非结构化数据转换为结构化数据等。
3、数据集成:将来自不同来源的数据进行整合,形成一个统一的数据视图。
4、数据分析:对整合后的数据进行分析,提取有价值的信息和知识。
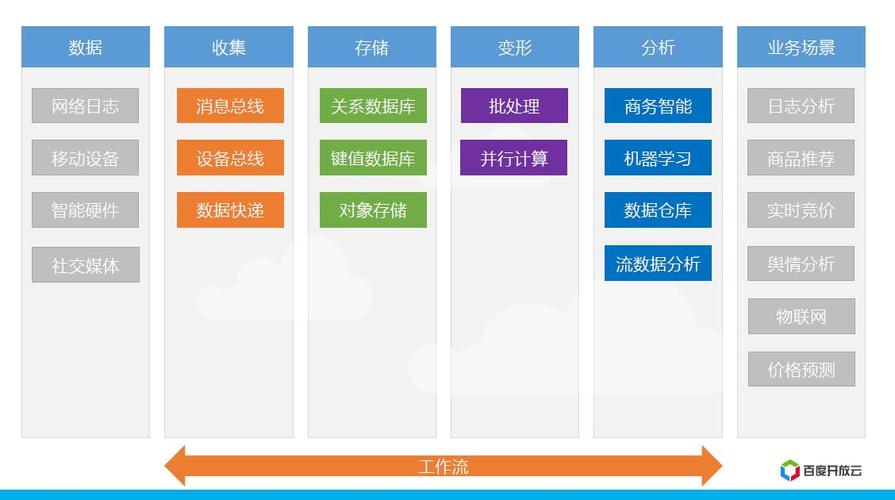
5、数据可视化:将分析结果以图表、图像等形式展示,帮助用户更直观地理解数据。
大量数据处理的工具和技术
1、Hadoop:一个开源的分布式计算框架,可以处理海量数据。
2、Spark:一个快速、通用的大数据处理引擎,支持多种数据处理任务。
3、Hive:一个基于Hadoop的数据仓库工具,可以将SQL语句转换为MapReduce任务。
4、Pig:一个基于Hadoop的数据流处理平台,支持复杂的数据分析任务。
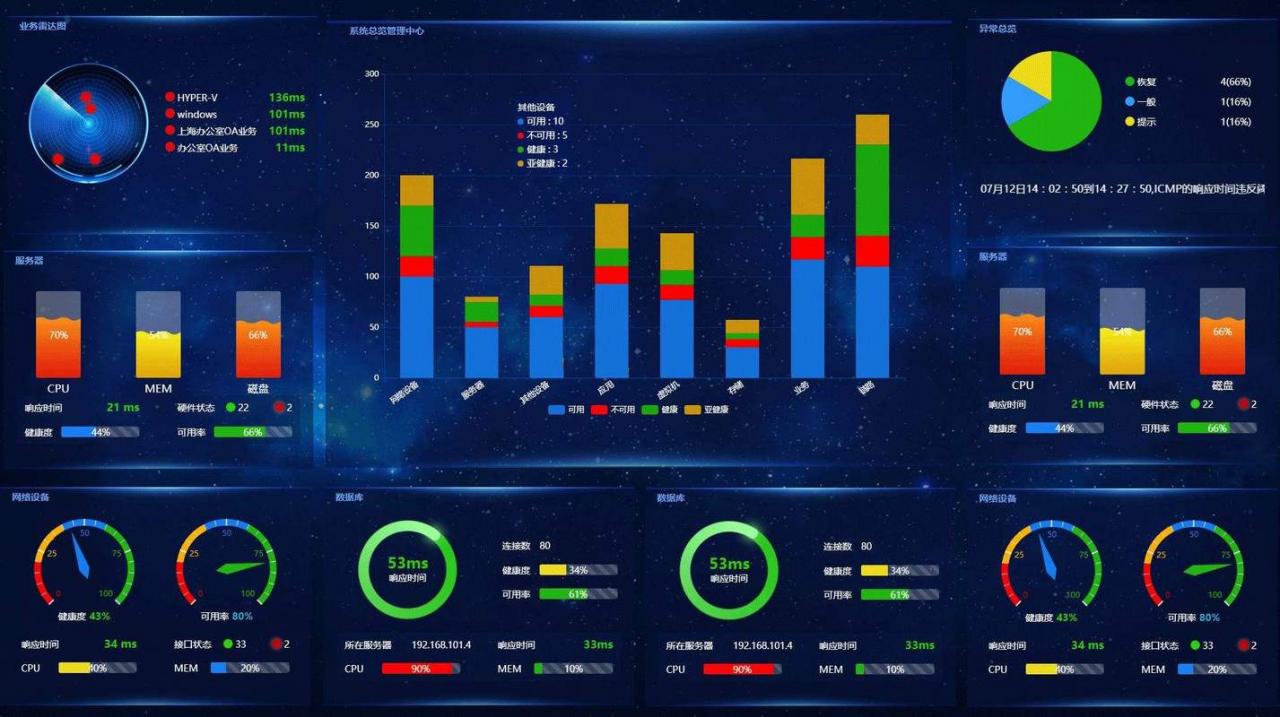
5、NoSQL数据库:如MongoDB、Cassandra等,用于存储非结构化数据。
大量数据处理的挑战
1、数据量巨大:需要处理的数据量远远超过传统数据库的处理能力。
2、数据类型多样:需要处理的数据类型包括结构化数据和非结构化数据。
3、数据处理速度:需要在短时间内完成大量数据的处理和分析。
4、数据质量:需要保证处理后的数据质量,避免因为数据质量问题导致错误的分析结果。
相关问题与解答
问题1:如何处理大量非结构化数据?
答:可以使用NoSQL数据库来存储非结构化数据,如MongoDB、Cassandra等,还可以使用Hadoop、Spark等大数据处理框架来处理非结构化数据。
问题2:如何提高大量数据处理的速度?
答:可以通过以下方法提高大量数据处理的速度:1) 优化数据处理算法;2) 使用高性能的硬件设备;3) 使用分布式计算框架,如Hadoop、Spark等;4) 对数据进行预处理,减少不必要的计算。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/547870.html
 微信扫一扫
微信扫一扫