

大数据宽表是一种用于存储和管理大量数据的表格结构,通常具有以下特点:
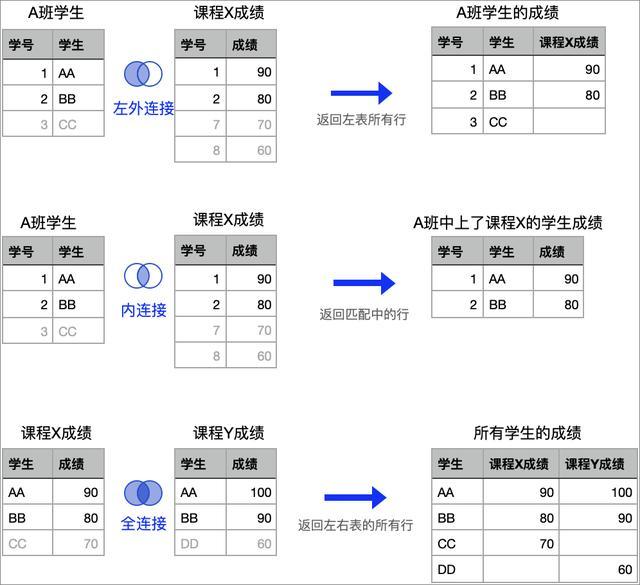

1、大量的列(字段):宽表包含许多列,每个列代表一个数据字段,这些列可以包含各种类型的数据,如文本、数值、日期等。
2、较少的行(记录):与传统的关系型数据库中的窄表相比,宽表中的行数相对较少,这是因为宽表主要用于聚合和分析数据,而不是存储详细的个体记录。
3、稀疏性:由于宽表中的列非常多,但每行可能只包含其中的一部分列的值,因此宽表通常是稀疏的,这意味着大部分单元格都是空值或零值。
4、高维度:宽表的列数较多,因此其维度较高,这使得宽表能够表示复杂的数据集,并支持多种数据分析和挖掘任务。
基础配置宽表配置:
1、列定义:在创建宽表时,需要定义每一列的名称、数据类型和约束条件,可以使用VARCHAR类型来存储文本数据,使用INT类型来存储整数数据等。
2、分区:为了提高查询性能和数据管理效率,可以将宽表按照某个逻辑进行分区,常见的分区方式包括按时间范围、按地域范围等。
3、索引:为了加快查询速度,可以在宽表的某些列上创建索引,索引的选择应根据查询需求和数据分布情况来确定。
4、压缩:由于宽表中可能存在大量的空值或零值,可以采用压缩算法对数据进行压缩,以减少存储空间和提高查询性能。
5、分区键和排序键:在分区表中,需要指定分区键和排序键,分区键用于确定数据所在的分区,而排序键用于在每个分区内对数据进行排序。
相关问题与解答:
问题1:如何优化大数据宽表的查询性能?
答:优化大数据宽表的查询性能可以采取以下措施:
创建合适的索引:根据查询需求和数据分布情况,选择适当的列创建索引,以提高查询速度。
分区和分桶:将宽表按照某个逻辑进行分区或分桶,可以减少扫描的数据量,提高查询效率。
缓存机制:对于频繁访问的数据,可以采用缓存机制来提高查询速度。
并行处理:利用分布式计算框架的特性,将查询任务分解为多个子任务并行执行,以提高查询速度。
问题2:如何处理大数据宽表中的稀疏性?
答:处理大数据宽表中的稀疏性可以采取以下方法:
数据编码压缩:使用压缩算法对稀疏数据进行编码压缩,以减少存储空间和提高查询性能。
列式存储格式:采用列式存储格式(如Parquet)来存储稀疏数据,可以提高读取效率和降低存储成本。
数据采样:对于稀疏数据,可以采用采样技术来减少数据量,同时保持数据的代表性。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/548858.html
 微信扫一扫
微信扫一扫