

监控指标含义
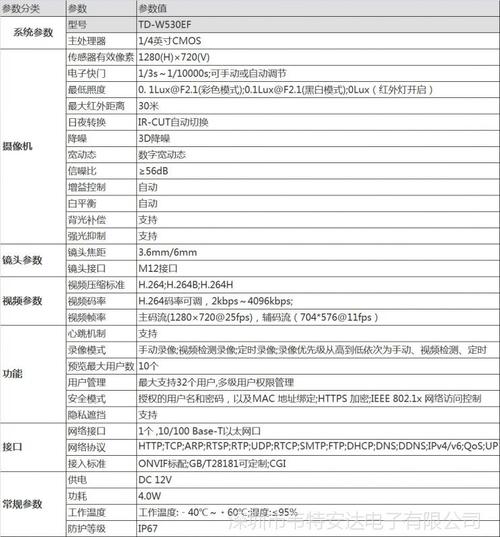

在信息技术(IT)和运维管理领域,监控指标是衡量系统、服务或网络性能的关键参数,这些指标帮助管理员识别问题、优化性能并确保服务的可靠性,以下是一些常见的监控指标及其详细含义:
1. CPU使用率 (CPU Usage)
含义: CPU使用率指的是处理器在特定时间内被占用的百分比,它反映了处理器的忙碌程度。
重要性: 高CPU使用率可能表明应用程序过载或存在效率低下的代码。
2. 内存使用率 (Memory Usage)

含义: 内存使用率展示了系统内存的使用情况,包括物理内存和虚拟内存的使用百分比。
重要性: 高内存使用可能导致系统响应缓慢,甚至出现内存溢出错误。
3. 磁盘I/O (Disk I/O)
含义: 磁盘输入输出操作的频率和量度,通常分为读取和写入两种操作。
重要性: 频繁的磁盘I/O操作可能影响应用的性能,特别是在数据密集型的应用中。
4. 网络吞吐量 (Network Throughput)
含义: 网络吞吐量是指在单位时间内通过网络的数据量,通常以比特每秒(bps)计量。
重要性: 低网络吞吐量可能导致数据传输延迟,影响用户体验。
5. 系统负载 (System Load)
含义: 系统负载表示在特定时间点等待运行和正在运行的进程数。
重要性: 高系统负载可能导致系统响应变慢,处理新请求的能力下降。
6. 响应时间 (Response Time)
含义: 响应时间是指从发送请求到接收响应所需的时间。
重要性: 长的响应时间通常是性能瓶颈的标志,需要优化相关组件。
7. 错误率 (Error Rate)
含义: 错误率是指在所有请求中出错的比例。
重要性: 高错误率可能指示系统不稳定或有缺陷的代码。
8. 并发连接数 (Concurrent Connections)
含义: 并发连接数是指在任何给定时刻与服务器建立的活跃网络连接的数量。
重要性: 高并发连接数可能表明服务器承载能力的压力测试。
9. 事务吞吐量 (Transaction Throughput)
含义: 事务吞吐量是指单位时间内完成的事务数量。
重要性: 这个指标对于数据库和事务处理系统尤为重要,可以反映系统的处理能力。
10. 可用性 (Availability)
含义: 可用性是指系统正常运行的时间比例。
重要性: 高可用性是确保业务连续性和用户满意度的关键。
表格总结
| 指标 | 含义 | 重要性 |
| CPU使用率 | CPU在特定时间内被占用的百分比 | 反映处理器忙碌程度,高使用率需优化 |
| 内存使用率 | 系统内存的使用情况 | 高使用率可能导致系统响应缓慢 |
| 磁盘I/O | 磁盘读写操作的频率和量度 | 频繁操作影响性能 |
| 网络吞吐量 | 单位时间内通过网络的数据量 | 低吞吐量导致数据传输延迟 |
| 系统负载 | 等待运行和正在运行的进程数 | 高负载降低系统响应速度 |
| 响应时间 | 从发送请求到接收响应的时间 | 长响应时间指示性能瓶颈 |
| 错误率 | 在所有请求中出错的比例 | 高错误率显示系统不稳定或有缺陷代码 |
| 并发连接数 | 与服务器建立的活跃网络连接的数量 | 高并发连接数测试服务器承载能力 |
| 事务吞吐量 | 单位时间内完成的事务数量 | 反映系统的处理能力 |
| 可用性 | 系统正常运行的时间比例 | 确保业务连续性和用户满意度 |
相关问题与解答
Q1: 如果发现CPU使用率持续很高,应该采取哪些措施?
A1: 如果CPU使用率持续很高,可以采取以下措施:
性能分析: 使用工具如top,perf, 或pidstat来分析哪些进程或线程消耗最多CPU资源。
代码优化: 根据分析结果,对消耗资源的代码进行优化,减少不必要的计算和循环。
增加资源: 如果系统资源不足以支持当前的工作负载,考虑升级硬件或增加更多的计算资源。
负载均衡: 在多个服务器之间分配工作负载,减轻单一服务器的压力。
Q2: 如何提高系统的可用性?
A2: 提高系统可用性的方法包括:
冗余设计: 通过设置冗余系统(如双活或热备)来防止单点故障。
定期维护: 实施定期的系统检查和维护,预防潜在故障。
灾难恢复计划: 制定并测试灾难恢复计划,以确保在发生故障时能快速恢复服务。
监控系统: 实施综合监控系统来实时检测和解决可能影响可用性的问题。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/552527.html
 微信扫一扫
微信扫一扫