

大数据核心特性,体量巨大、类型多样、处理快速、价值密集。,,1. 数据体量巨大(Volume):指的是数据的规模非常庞大,远超传统数据库能够处理的范畴。这种数据可以来自各种渠道,包括商业交易、社交媒体内容、传感器数据等。,2. 数据类型繁多(Variety):大数据不仅量大,其类型也非常多样,包括结构化数据、半结构化数据和非结构化数据,这些多样的数据类型增加了数据分析的复杂性。,3. 数据生成速度快(Velocity):数据不仅量大和多样化,而且产生的速度非常快。这要求数据处理系统能够实时或几乎实时地处理和分析数据,以便及时做出响应和决策。,4. 数据真实性(Veracity):数据的真实性和准确性也是大数据的一个关键特性。由于数据来源广泛,数据的质量可能参差不齐,这对数据分析和后续的决策制定提出了挑战。,5. 数据价值(Value):大数据的价值在于能够从这些庞大的数据集中提取出有用的信息和洞察,帮助企业和组织改进业务过程、预测未来趋势和做出更智能的决策。,,大数据的这些特性共同定义了它的基本构架和应用领域,同时也指出了在管理和分析大数据时面临的主要挑战。理解和利用这些特性,能够帮助企业和组织更好地挖掘数据潜力,实现数据驱动的决策和创新。在探索大数据的应用时,重视其体量、多样性、处理速度和数据质量是保证成功实施的关键。
大数据特性
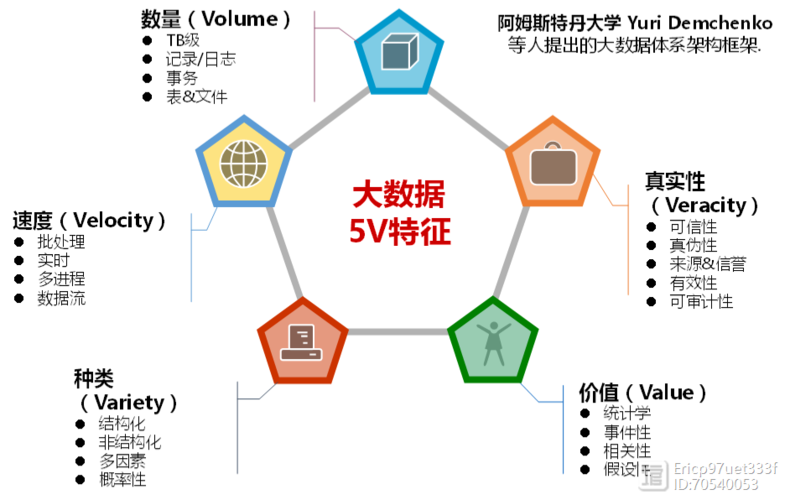

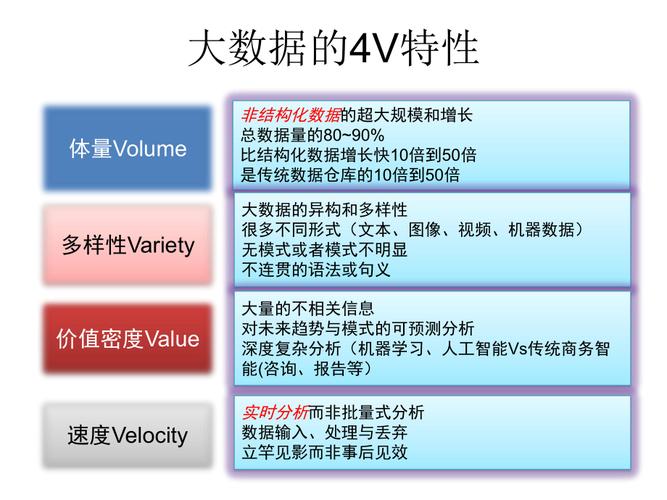
大数据是指无法在合理时间内通过常规数据库软件工具进行管理和处理的大规模数据集合,它通常具有以下四个核心特性,也被称为大数据的四个“V”。
1. 体积(Volume)
大数据的体积巨大,这指的是数据的规模非常庞大,以至于传统的数据处理方法不再有效,数据可以来自各种渠道,如社交媒体、传感器、日志文件等。
| 来源 | 描述 |
| 社交媒体 | 用户生成的内容和交互数据 |
| 传感器 | 物联网设备产生的实时数据 |
| 日志文件 | 系统和应用程序的操作记录 |
2. 速度(Velocity)
数据的生成速度极快,需要实时或接近实时的处理,金融市场交易数据、社交媒体更新、在线交易等都是高速生成的数据源。

| 类型 | 描述 |
| 实时数据流 | 需要立即处理以支持决策 |
| 批量数据 | 定期生成的大量数据,但不需要即时处理 |
3. 多样性(Variety)
数据可以是结构化的、半结构化的或非结构化的,结构化数据遵循固定模式,半结构化数据只有部分结构,而非结构化数据则没有预定义的结构。
| 类别 | 描述 | 示例 |
| 结构化数据 | 有明确格式的数据 | 数据库表格 |
| 半结构化数据 | 格式不固定,但包含标签或元数据 | JSON, XML |
| 非结构化数据 | 无固定格式的数据 | 文本、图片、视频 |
4. 真实性(Veracity)
数据的真实性涉及数据的质量和可信度,由于数据可能来自不同的源头和格式,其准确性和可靠性可能会有所不同。
| 问题 | 影响 |
| 数据质量 | 错误的、过时的或不完整的数据会影响分析结果 |
| 数据来源 | 来源不明的数据可能不够可信 |
相关问题与解答
Q1: 大数据的第五个V是什么?
A1: 除了体积、速度、多样性和真实性这四个核心特性之外,有时也会提到大数据的第五个V——价值(Value),这指的是从大量数据中提取出有用信息的能力,以及这些信息对业务的价值。
Q2: 如何处理大数据的多样性问题?
A2: 处理大数据的多样性问题通常需要使用多种技术和工具,对于结构化数据,可以使用传统的关系型数据库管理系统;对于半结构化数据,可以使用NoSQL数据库或专门的解析工具;对于非结构化数据,则需要使用文本分析、图像识别或自然语言处理等技术,数据整合和清洗也是处理多样性问题的关键步骤,以确保数据质量和一致性。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/553854.html
 微信扫一扫
微信扫一扫