

广度优先遍历(Breadth-First Search, BFS)是一种用于图的遍历搜索算法,在任务优先级中,广度优先遍历可以用于确定任务执行的顺序,确保按照特定的规则或条件来处理任务。

广度优先遍历基础
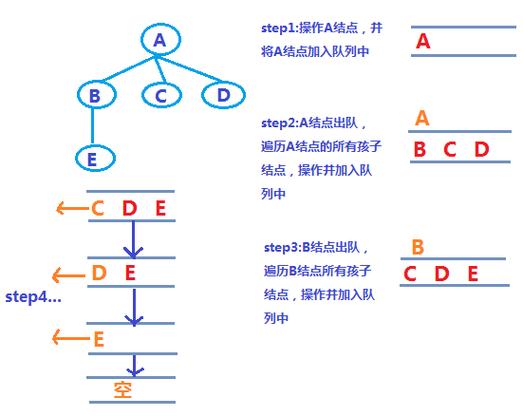
广度优先遍历从起始节点开始,首先访问其所有直接邻居,然后再逐层向下访问更远的节点,这种遍历方式通常使用队列来实现,以下是广度优先遍历的基本步骤:
1、将起始节点加入队列。
2、当队列非空时,执行以下操作:
取出队头的节点。
访问该节点,并对其执行相关操作。
将该节点的所有未访问邻居加入队列。
3、标记已访问的节点,避免重复访问。
4、重复上述过程,直到队列为空。
任务优先级中的应用
在任务优先级中,广度优先遍历可以用于确定任务执行的顺序,在一个项目管理系统中,任务之间可能存在依赖关系,在这种情况下,可以使用广度优先遍历来确定哪些任务应该先完成,以确保所有任务都能在满足其依赖关系的前提下顺利完成。
示例:任务依赖关系图
假设有如下任务依赖关系图:
A → B → C \ / → D →
箭头表示任务之间的依赖关系,任务 B 依赖于任务 A,根据这个依赖关系图,我们可以使用广度优先遍历来确定任务的执行顺序。
广度优先遍历实现
1、将起始任务 A 加入队列。
2、访问任务 A,并将其直接依赖的任务 B 和 D 加入队列。
3、访问任务 B,并将其直接依赖的任务 C 加入队列。
4、访问任务 D(此时没有新的依赖任务)。
5、访问任务 C。
结果
按照广度优先遍历的顺序,任务执行的顺序应该是:A, B, D, C。
单元表格
| 步骤 | 当前任务 | 入队任务 | 出队任务 | 状态 |
| 1 | A | B, D | A | 已完成 |
| 2 | B | C | B | 已完成 |
| 3 | D | D | 已完成 | |
| 4 | C | C | 已完成 |
问题与解答
1、问题: 如果存在循环依赖关系,广度优先遍历如何处理?
解答: 广度优先遍历本身不检测循环依赖关系,在实际应用中,需要预先检查图中是否存在循环依赖,并在遍历之前解决这些依赖,以避免无限循环。
2、问题: 如何修改广度优先遍历算法以适应加权边的情况?
解答: 在加权边的情况下,广度优先遍历算法本身不需要修改,但需要根据边的权重来决定访问顺序,这通常通过使用优先级队列来实现,其中优先级由边的权重决定,这样,具有较低权重(较高优先级)的节点将首先被访问。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/554085.html
 微信扫一扫
微信扫一扫