

多语种网站_多语种文本分类工作流
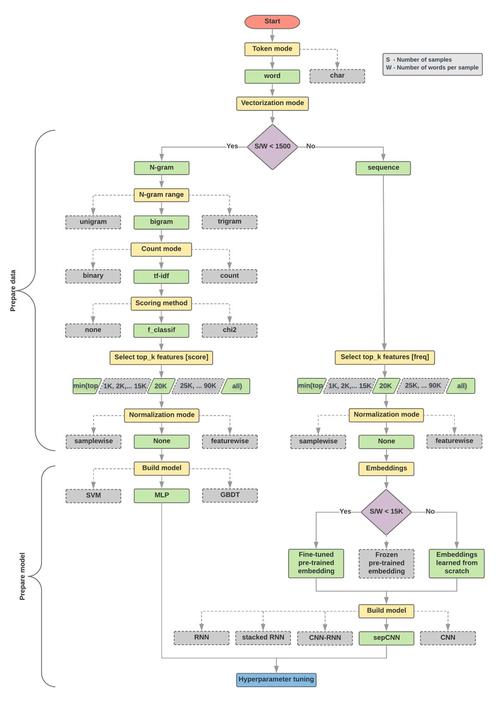

在全球化的今天,许多企业都拥有多语种的网站来吸引和服务不同语言的用户,为了有效管理和组织这些内容,需要进行多语种文本分类,以下是详细的多语种文本分类工作流:
1. 数据收集
需要从网站上收集各种语言的文本数据,这通常通过爬虫程序来实现,它可以自动访问网站并提取所需的文本信息。
2. 数据预处理
收集到的数据可能包含许多无用的信息,如HTML标签、广告等,需要进行数据清洗和预处理,包括去除无用信息、纠正错误等。
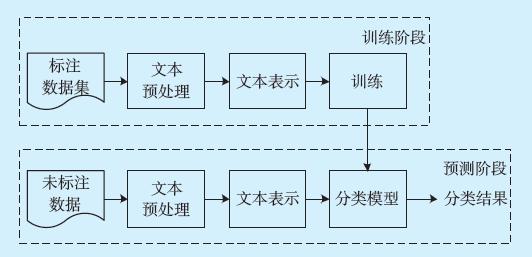
3. 文本分词
对于每种语言,都需要进行文本分词,将句子分解为单词或词语,这一步是后续处理的基础。
4. 特征提取
在文本分词后,可以提取出一些有用的特征,如词频、TFIDF值等,这些特征将用于后续的分类任务。
5. 模型训练

使用上述提取的特征,可以训练一个分类模型,这个模型可以是传统的机器学习模型,如SVM、决策树等,也可以是深度学习模型,如CNN、RNN等。
6. 模型评估
训练完模型后,需要对其进行评估,看看其在测试数据上的表现如何,常用的评估指标有准确率、召回率、F1值等。
7. 模型部署
如果模型的表现满意,就可以将其部署到生产环境中,对新的数据进行分类。
相关问题与解答
Q1: 如果网站的语言种类很多,是否需要为每种语言都训练一个模型?
A1: 理论上,可以为每种语言都训练一个模型,但在实际操作中,如果某些语言的数据量很小,可能会导致模型过拟合,可以考虑将这些小语种的数据合并,共同训练一个模型。
Q2: 如何处理新出现的语言?
A2: 对于新出现的语言,首先需要收集该语言的数据,然后按照上述流程进行处理,如果该语言与已有的某些语言很相似(如荷兰语和德语),可以考虑使用迁移学习的方法,利用已有语言的模型来帮助新语言的模型训练。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/555782.html
 微信扫一扫
微信扫一扫