

开启Kafka高可靠功能


Apache Kafka是一个分布式流处理平台,它被设计用来处理大量实时数据,在保证数据可靠性方面,Kafka提供了一系列的机制来确保消息的持久性和一致性,本白皮书将详细介绍如何开启和配置Kafka的高可靠特性,以确保数据在传输和存储过程中的安全性与稳定性。
基本概念
Kafka的可靠性层级
1、Broker Reliability 确保broker节点的数据不丢失。
2、Topic Reliability 保证主题内的数据不丢失。

3、Producer Reliability 生产者发送的消息确保被broker接收。
4、Consumer Reliability 消费者能够正确地消费消息。
数据同步机制
Replication Kafka通过副本机制实现数据的冗余备份。
Leader Election 当leader broker失效时,会从isr(InSync Replicas)中选举新的leader。
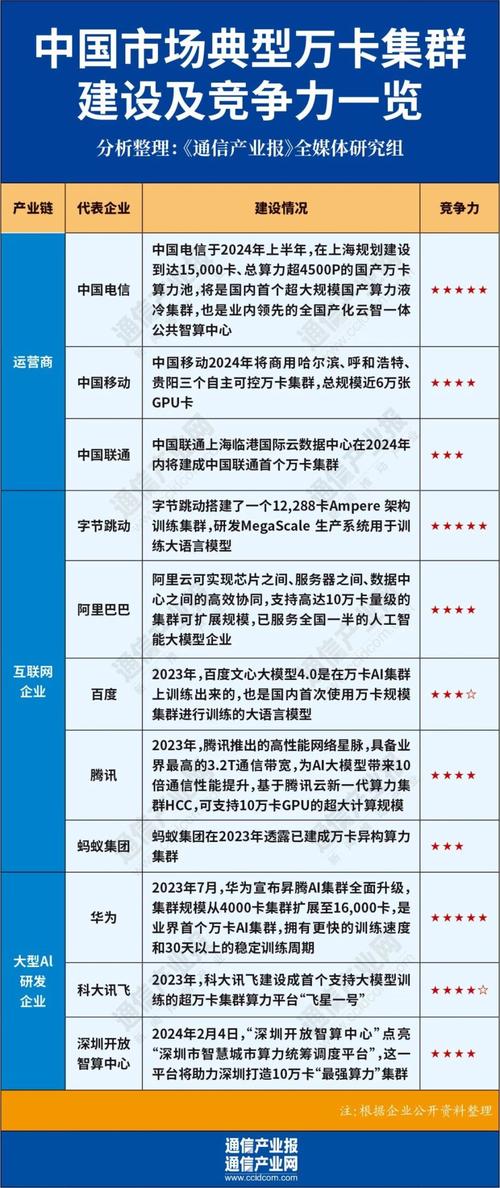
Log Compaction 合并消息日志,删除冗余消息,保留每个键的最新值。
配置步骤
1. 配置broker
在server.properties文件中进行如下配置:
| 参数 | 说明 | 推荐值 |
default.replication.factor |
设置每个分区的副本数量 | ≥3 |
min.insync.replicas |
设置最小同步副本数 | ≥2 |
unclean.leader.election.enable |
是否允许非ISR中的副本成为leader | false |
log.retention.hours |
日志保存时间 | 根据业务需求设定 |
2. 配置topic
创建或修改topic时,可以指定以下参数:
bin/kafkatopics.sh create zookeeper localhost:2181 replicationfactor 3 partitions 3 topic myhighreliabletopic
3. 配置producer
在producer.properties文件中进行如下配置:
| 参数 | 说明 | 推荐值 |
acks |
消息发送成功的确认级别 | all |
retries |
发送失败时的重试次数 | ≥3 |
4. 配置consumer
在consumer.properties文件中进行如下配置:
| 参数 | 说明 | 推荐值 |
isolation.level |
消费者的隔离级别 | read_committed |
enable.auto.commit |
是否自动提交偏移量 | false |
监控与维护
JMX监控 使用JMX工具监控Kafka的性能指标。
日志审计 定期审计broker的日志文件,检查异常。
集群健康检查 使用工具如Apache Kafka Manager定期检查集群状态。
通过上述配置和最佳实践,可以显著提高Kafka集群的可靠性,保障数据的安全传输和持久化存储,需要注意的是,增加副本和分区数量会增加资源消耗,因此在实际应用中需要根据业务需求和系统资源进行权衡。
Q&A
Q1: Kafka的副本机制是如何工作的?
A1: Kafka通过多副本机制来实现数据的高可用性,每个分区都会有一个leader副本和多个follower副本,leader负责处理所有的读写请求,而followers则从leader复制数据,即使leader副本发生故障,其他follower副本中的一个会被提升为新的leader,从而继续提供服务。
Q2: 如果生产者设置了acks=all,但某个副本没有正常写入,会发生什么情况?
A2: 当acks=all时,意味着只有当所有同步副本都接收到消息时,生产者才会认为消息写入成功,如果有副本未能正常写入,生产者会收到一个错误响应,并根据配置的重试策略进行重试,如果重试后仍然失败,那么消息会被认为是未成功发送,并可能触发生产者的错误处理逻辑。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/557706.html
 微信扫一扫
微信扫一扫