

高斯混合模型(Gaussian Mixture Model,简称GMM)是一种概率模型,它假设所有数据点都是由K个高斯分布生成的,每个高斯分布称为一个组件或簇,每个数据点都有其对应的组件。
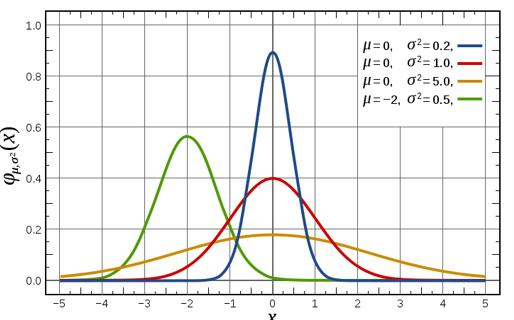

高斯混合模型的定义和组成
高斯混合模型是多个高斯分布函数的线性组合,可以表示为:
\[ p(x| \lambda) = \sum_{i=1}^{M} w_i g(x; \mu_i, \Sigma_i) \]
\( x \) 是连续值数据向量;
\( \lambda \) 是模型参数集;

\( M \) 是单高斯分布的数量;
\( w_i \) 是混合权重,满足 \( \sum_{i=1}^{M} w_i = 1 \);
\( g(x; \mu_i, \Sigma_i) \) 是单个高斯分布,\( \mu_i \) 是均值向量,\( \Sigma_i \) 是协方差矩阵。
每个高斯组件可以有不同的均值和协方差。
高斯混合模型的参数估计
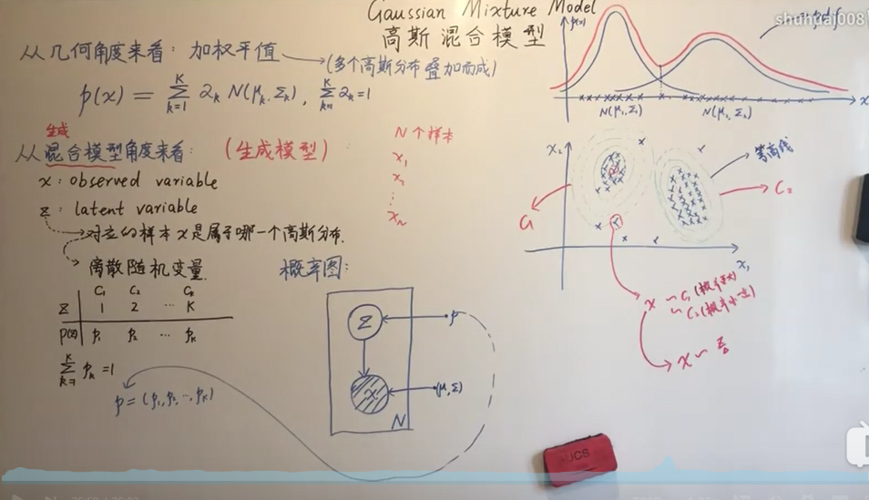
高斯混合模型通常使用期望最大化(EM)算法来估计参数,EM算法分为两个步骤:
E步骤(Expectation Step)
计算完全数据的对数似然的期望值,这里“完全”的意思是既包含观测到的数据也包含缺失的数据(即每个样本所属的高斯分布),这一步需要计算后验概率 \( \gamma(z_nk) \),即样本 \( x_n \) 来自第 \( k \) 个高斯分布的概率。
M步骤(Maximization Step)
最大化E步骤中计算出的对数似然的期望值,从而更新参数 \( w_k, \mu_k, \Sigma_k \)。
高斯混合模型的应用
GMM在许多领域都有应用,包括聚类分析、语音和图像处理、密度估计等,在聚类分析中,每个高斯分布代表一个簇,而数据点根据它们属于不同高斯分布的概率被分配到不同的簇中。
高斯混合模型的优点和缺点
优点
GMM能够形成复杂形状的密度,因为它是由多个高斯分布组成的。
它提供了一种软聚类方法,即每个数据点可以以不同的概率属于多个簇。
适用于大量数据集,特别是当数据呈现多模态分布时。
缺点
需要预先设定簇的数量,这通常是未知的。
对初始值敏感,不同的初始值可能会导致不同的最终解。
可能会收敛到局部最优解,而不是全局最优解。
对于非常高维的数据,GMM可能不是最佳选择。
高斯混合模型与其他模型的比较
GMM与其他聚类算法如Kmeans相比,提供了一种更灵活的方式来模拟数据点的概率分布,Kmeans算法通常更快,更容易实现,并且对大规模数据集更加高效。
实施高斯混合模型时的注意事项
选择合适的簇数量:可以通过交叉验证、BIC(贝叶斯信息准则)或AIC(赤池信息量准则)来确定。
初始化参数:可以使用Kmeans或其他方法来初始化均值,或者随机初始化。
避免过拟合:可以通过正则化或限制协方差矩阵的形式来实现。
单元表格:高斯混合模型与Kmeans的对比
| 特性 | 高斯混合模型 (GMM) | Kmeans |
| 类型 | 概率模型 | 确定性模型 |
| 聚类结果 | 软聚类,每个样本有属于每个簇的概率 | 硬聚类,每个样本仅属于一个簇 |
| 簇形状 | 可以形成椭圆形的簇 | 只能形成凸形的簇 |
| 适用数据类型 | 连续数据 | 连续数据 |
| 对初始值敏感性 | 较高 | 较低 |
| 执行速度 | 较慢 | 较快 |
| 收敛性质 | 可能收敛到局部最优解 | 收敛速度快,但可能是局部最优解 |
| 模型复杂度 | 较高,需要估计更多的参数 | 较低,只需要估计簇中心 |
| 扩展性 | 可以扩展到高斯混合回归等 | 可以扩展至Kmedians、Kmedoids等 |
| 鲁棒性 | 较弱,对噪声和异常值敏感 | 较强,对噪声和异常值不敏感 |
相关问答
问题1:如何选择GMM中的高斯分布数量?
答案:高斯分布的数量可以通过多种方法确定,包括:
交叉验证:通过分割数据集并测试不同数量的GMM配置来评估性能。
信息准则:如BIC(贝叶斯信息准则)或AIC(赤池信息量准则),它们结合了模型拟合度和复杂度。
直觉和经验:基于对数据的理解和先前的经验来选择。
可视化方法:如轮廓图或间隙统计。
问题2:GMM与Kmeans聚类相比有哪些优缺点?
答案:GMM相对于Kmeans聚类的主要优点在于:
它提供了一个概率框架,允许软聚类,即每个数据点可以按不同的概率属于多个簇。
GMM可以形成更复杂的簇形状,比如椭圆形,而Kmeans只能形成凸形的簇。
GMM的缺点包括:
对初始参数敏感,可能需要多次运行或使用不同的初始化策略来确保找到一个好的解。
比Kmeans计算成本更高,特别是在大数据集上。
GMM在实际应用中需要更多的参数调整和验证工作。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/558459.html
 微信扫一扫
微信扫一扫